企业的业务服务所产生的一些标准化表单、日志等数据文件,会被周期性的直接上传到OSS。但是这些存储在OSS的文件缺少元数据管理,导致难以分析和计算。元数据发现任务可以在单次运行中自动为OSS上面的数据文件创建和更新数据湖元数据(一张或多张表),具有自动探索文件数据字段及类型、自动映射目录和分区、自动感知新增列及分区、自动对文件进行分组建表的能力。
OSS数据源配置模式
OSS数据源配置支持数仓模式和自由模式,两种模式差异如下:
| OSS数据源配置 | 使用场景 | OSS路径格式要求 | 识别精度 | 性能 |
|---|---|---|---|---|
| 数仓模式 | 用户直接上传数据到OSS,并期望构建可分析与计算的标准数据仓库。 | 库/表/文件”或者“库/表/分区/.../分区/文件 | 高 | 高 |
| 自由模式 | 已存在OSS数据,但OSS的路径不清晰。期望通过元信息发现,构建可分析的库表分区。 | 无要求 | 一般 | 一般 |
数仓模式的OSS路径格式要求
OSS是一个开放的文件系统,为了高效的在OSS上面构建数据仓库,数据源路径格式需要有一定的规范性。OSS数据源数仓模式的元信息发现只支持库/表/文件或者库/表/分区/.../分区/文件的路径格式(根目录对应schema;第二级子目录对应Table,且子目录名需要映射到表名;第三级以上如果还有目录,就对应为分区)。如下图所示: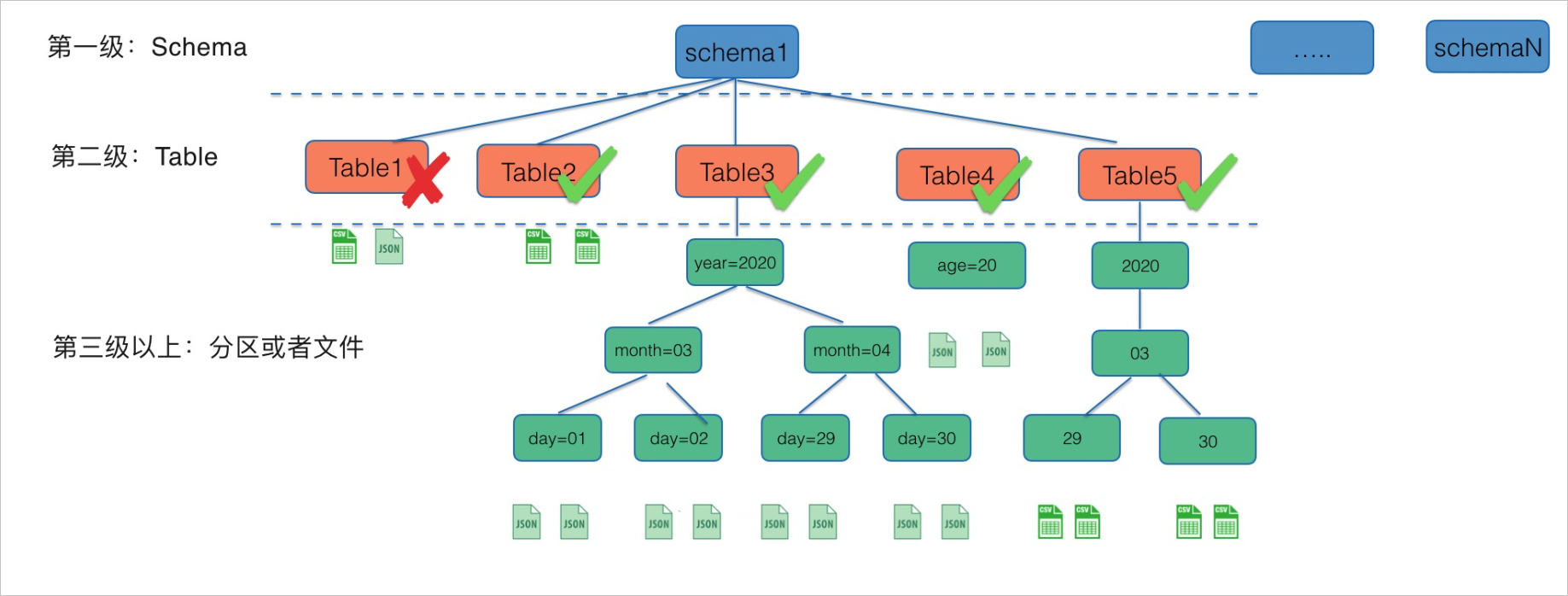
上图对应的OSS路径如下:
oss://xxx...xxx/schema1/Table1/file1.csv
oss://xxx...xxx/schema1/Table1/file2.json
oss://xxx...xxx/schema1/Table2/file3.csv
oss://xxx...xxx/schema1/Table2/file4.csv
oss://xxx...xxx/schema1/Table3/year=2020/month=03/day=01/file5.json
oss://xxx...xxx/schema1/Table3/year=2020/month=03/day=01/file6.json
oss://xxx...xxx/schema1/Table3/year=2020/month=03/day=02/file7.json
oss://xxx...xxx/schema1/Table3/year=2020/month=03/day=02/file8.json
oss://xxx...xxx/schema1/Table3/year=2020/month=04/day=29/file9.json
oss://xxx...xxx/schema1/Table3/year=2020/month=04/day=29/file10.json
oss://xxx...xxx/schema1/Table3/year=2020/month=04/day=30/file11.json
oss://xxx...xxx/schema1/Table3/year=2020/month=04/day=30/file12.json
oss://xxx...xxx/schema1/Table4/age=20/file13.json
oss://xxx...xxx/schema1/Table4/age=20/file14.json
oss://xxx...xxx/schema1/Table5/2020/03/29/file15.csv
oss://xxx...xxx/schema1/Table5/2020/03/29/file16.csv
oss://xxx...xxx/schema1/Table5/2020/03/30/file17.csv
oss://xxx...xxx/schema1/Table5/2020/03/30/file18.csv上述数仓模式的OSS数据源进行元信息发现后,在DLA中自动映射的表如下所述:
| OSS数据源目录名称 | DLA中自动映射的表名称 | 映射说明 |
|---|---|---|
| Table1 | 不创建表 | Table1目录下的文件类型为csv和json,不一致,故而不能进行映射创建表。同一目录下的文件类型必须一致才能进行映射。
说明 如果文件类型相同,但是文件里面的字段不是同一种类型也不能进行映射。
|
| Table2 | 创建表Table2 | Table2目录下的文件类型都为csv,可以进行映射。 |
| Table3 | 创建分区表Table3 | 分区格式为year=xx/month=xx/day=xx/。自动映射了以下分区:
|
| Table4 | 创建分区表Table4 | 分区格式为age=xx。自动映射了age=20分区。 |
| Table5 | 创建分区表Table5 | 分区格式为partition_0=xx/partition_1=xx/partition_2=xx/。自动映射了以下分区:
说明 由于没有分区键,这里使用partition_num来补充。
|
操作步骤
- 登录Data Lake Analytics管理控制台。
- 在左侧导航栏,单击。
- 在元信息发现页面的OSS数据源区域,单击进入向导。

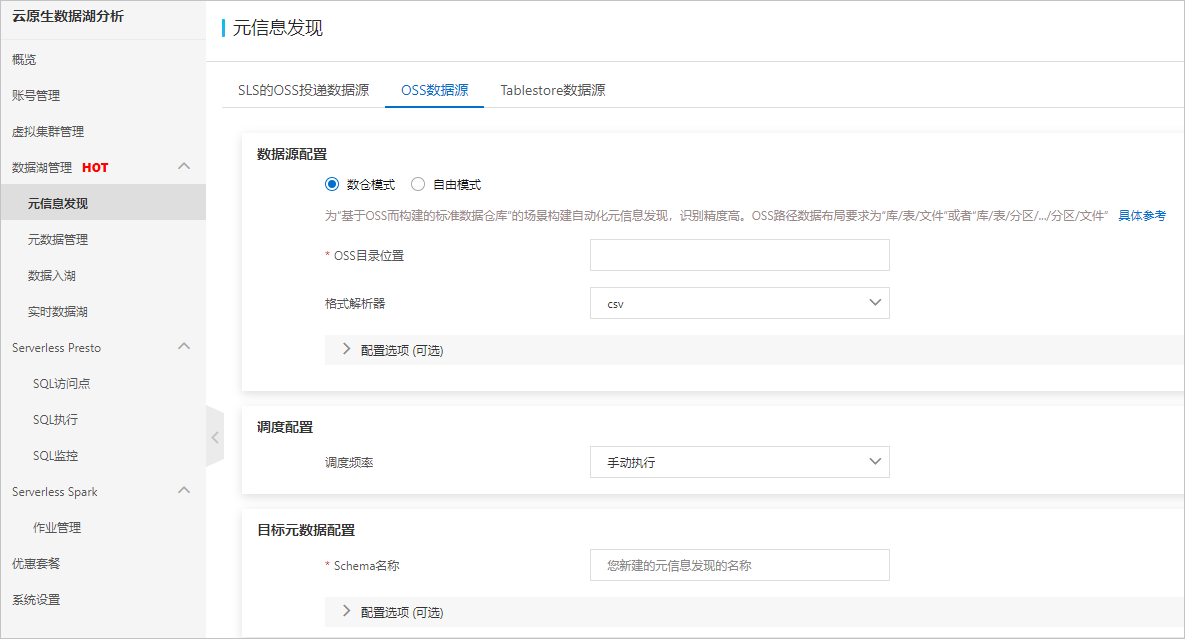
- 在OSS数据源页签,根据页面提示进行参数配置,配置说明如下:
参数 说明 数仓模式和自由模式 您可以选择数仓模式或自由模式: - 数仓模式:为“基于OSS而构建的标准数据仓库”的场景构建自动化元信息发现,识别精度高。OSS路径数据布局要求为“库/表/文件”或者“库/表/分区/.../分区/文件”。
- 自由模式:为“探索OSS上的数据进行分析”的场景构建自动化元信息发现。对OSS数据布局没有要求,可能会产生差异化的表。
OSS目录位置 文件在OSS中的存储地址,以/结尾。系统会根据您选择的文件夹路径,自动设置OSS路径。 说明 系统会自动拉取与DLA同地域的OSS Bucket,您可以根据业务需要从下拉列表中选择Bucket。选择Bucket后,系统会自动列出该Bucket下所有的Object和文件;选中目标Object和文件后,系统会自动将其添加到右侧的OSS路径处。格式解析器 格式解析器会读取数据文件内容,从而确定文件的数据格式。默认自动解析,即按照顺序调用所有内置解析器,也可指定特定文件类型的格式解析器,比如json、parquet、avro、orc、csv。 - json:需要读取文件开头以确定文件格式。
- parquet:需要读取文件结尾处的schema以确定文件格式。
- avro:需要读取文件开头处的shema以确定文件格式。
- orc:要读取文件元数据以确定文件格式。
- csv:检查以下分隔符:逗号(,)、竖线(|)、制表符(\t)、分号(;)、空格( )、(\u0001)。
配置选项 高级自定义设置项,如更新,删除规则等。 调度频率 您可以根据需要定期计划运行元信息发现任务。 Schema名称 设置Schema名称,即映射到DLA中的数据库名称(默认每个发现任务会新创建一个独立的Schema)。 - 完成上述参数配置后,单击创建,开始创建元信息发现任务。
说明 元信息发现任务创建完成后,DLA自动在您设定的时间周期运行发现任务,如果您想立即同步数据,也可以在任务列表选择立即执行。
- 任务开始运行后,会在实例列表显示任务实例的当前运行状态。也可以在任务列表界面管理任务的运行情况,支持查看任务的运行状态、配置的修改、跳转到DLA的SQL窗口进行快速的数据查询。
注意事项
数仓模式的注意事项如下:
- 如果OSS数据源路径没有被DLA识别出来,您需要查看路径下的文件类型是否相同。如果是CSV文件,您可以在解析器CSV中配置具体的参数比如分隔符、转义字符、是否有表头等。
- 由于元信息发现通过采样的方式并不能覆盖所有的记录,如果不同行的字段变化很大,会出现生成的表字段减少的情况。
- 在识别分区及表的时候,只支持子目录下只有文件的场景。如果目录下既有子目录又有文件,则该目录会被忽略掉,从而导致分区没有生成。
自由模式的注意事项如下:
- 元信息发现会如何生成表名
元信息发现会自动为它创建的表生成名称。存储在元数据管理schema目录中的表的名称遵循以下规则:
- 默认使用最后一级目录名作为表名(针对OSS数据文件)。
- 仅允许使用字母、数字、字符和下划线(_)。
- 表名的最大长度不能超过 128 个字符。发现程序会截断生成的名称以适应限制范围。
- 如果遇到重复的表名,则元信息发现会在表名后添加MD5字符串后缀。
- 元信息发现如何创建分区
当元信息发现扫描OSS目录文件并检测到多个文件时,它会在目录结构中确定表的根目录,以及哪些目录是表的分区。
表的名称基于OSS目录前缀或目录名,当某个目录级别下大部分的目录结构和文件格式都相同时,发现程序会创建一张分区表。例如,对于以下OSS目录结构:oss://bucket01/folder1/table1/partition1/fiile.txt oss://bucket01/folder1/table1/partition2/fiile.txt oss://bucket01/folder1/table2/partition3/fiile.txt oss://bucket01/folder1/table2/partition4/fiile.txt因为table1和table2下的目录和文件内容都是相似的,所以发现程序将创建一个具有两个分区列的表。分区列分别为partition_0(table这一级目录)、partition_1(partition这一级目录)。
对于以下OSS目录结构:oss://bucket01/folder1/table1/partition1/fiile.csv oss://bucket01/folder1/table1/partition2/fiile.csv oss://bucket01/folder1/table2/partition3/fiile.json oss://bucket01/folder1/table2/partition4/fiile.json因为table1和table2下的文件格式不同,所以发现程序将创建两张具有一个分区列的表。table1分区列包含partition1和partition2,table2分区列包含partition3和partition4。
对于采用key=value样式的Hive风格分区路径,发现程序会使用键名自动填充列名称。否则,它使用默认名称,如partition_0、partition_1 等。