数据访问代理服务端内部使用连接池访问物理数据库。合理的连接参数配置不仅有助于提升数据访问性能,而且能够保障数据库的稳定性。
以下是一些常见的服务端连接参数:
超时时间
connectTimeout:创建数据库连接超时时间。socketTimeout:SQL 请求超时时间,操作系统 socket 的超时时间,即一次 SQL 请求如果在该时间内没有返回任何数据,操作系统会抛出 Read timeout 的异常。txTimeout:数据访问代理事务超时时间,默认为 10 分钟。该参数是为了保护 ODP 的连接池不会被长事务占满,而影响业务的正常访问。目前该值不能修改,后续提供业务自定义配置。
idleTimeoutMinutes:连接空闲时间,超过该时间则会被剔除出连接池,默认为 12 分钟。其他参数:其他高级连接参数,可以在
connectionProperties通过 KV 键值对进行配置。连接数量:
min:单个分库的最小连接数。如果min> 0,启动时会自动创建min个连接。max:单个分库的最大连接数。
批量任务导入导出配置
当您需要进行批量导入/导出任务时,您可以对以下参数进行配置。
设置
connectionProperties中的socketTimeout=1000000参数,该参数是指指从连接池获取到连接的超时时间,推荐设置为较大值,如 1000000(16 分钟),单位为毫秒。
设置
connectionProperties中的rewriteBatchedStatements=true参数,该参数可以帮您批量执行SQL,需要导入数据的时候推荐设置为 true,这样批量插入时多条insert sql会被改写为一条。设置
newConnectionSql中的set @@ob_query_timeout=2000000000和set @@ob_trx_timeout= 2000000000参数,当使用 OceanBase 数据库的时候需要设置这两个值,单位是微秒。
并且此时数据库用户需要使用 odp_migrator 这个账号,当使用此账号时会启用 ODP 内部的流式结果集读取,不会因为单条 SQL 的结果集太大而把 ODP 的内存打爆。
连接池配置
数据库连接池
应用与数据库之间的连接建立和销毁是个大消耗的操作,为了避免每一个请求都进行此操作,于是有了数据库连接池。它的基本原理是连接建立后,先不销毁,而是放回连接池,当有新的请求,不再创建新的连接,而是从连接池中去申请获取已有连接直接使用,这样就避免了频繁的连接创建和销毁。连接池有两个最关键的参数:
最小连接数:连接池中始终维持的最小连接数。
最大连接数:允许创建的最大连接数。
合理的设置这两个参数才能最大化连接池的好处。如果最小连接数设置得过大,容易造成连接过剩;如果最大链接数设置得过大,有可能超过数据库的处理能力。由于连接池是无法感知数据库的运行情况以及负载的,所以建议通过以下两种办法来使得参数值趋于合理:
理论计算模型估算基准值:连接池本质是个排队系统,因此可以根据利特尔法则(Little's Law)来计算连接数。连接池中的连接数(L)= 单位时间内的 SQL 请求量 * SQL 请求耗时(W),最开始可以以此估算一个值作为基准。
利用压测和实际运行监控调整:QPS 和请求耗时需要应用运行时持续监控才能得出更合理的值,同时还需利用压测来模拟大业务量和高并发场景,结合两种情况进行调整得到合理值。
ODP 连接池
在应用使用数据访问代理 ODP 进行分库分表的场景里,整体工作链路如下:
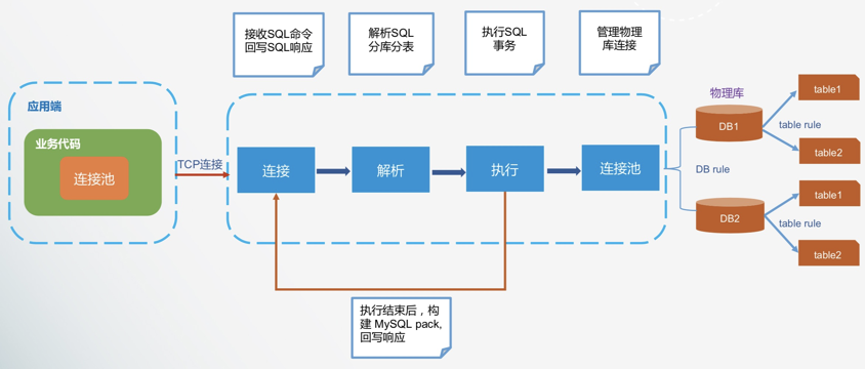
示例
假设业务的预估值是:QPS 是 10000;请求耗时日常是 2ms,最高是 10ms。
根据前面提到的利特尔法则,需要的连接数 10000*0.002=20 个,最高为 10000*0.01=100 个,也就是最小连接数(MIN)20,最大连接数(MAX)100。那么对于应用侧的连接池,假设应用节点个数为 4,连接数则可以设置为 MIN=20/4=5,MAX=100/4=25。
ODP 获取请求后,期望是无缝转发给数据库,所以需要的最小连接数与应用一致最小是 20,最大连接数则还需额外考虑两个因素:
分库数量:考虑到最高耗时,同样最大连接数为 100 个。
数据库规格:根据 10000 QPS,至少需要一个 m1-medium 的 RDS 实例,对应的最大连接数是 4000。
综合考虑,最大连接数一般为基于 QPS 计算出的最大值的两倍,并且必须需要小于数据库规格最大值,因此建议为 100*2=200。由于 ODP 管控界面上的最小最大连接数是对应到的是单个 ODP 节点针对单个库的连接池配置,所以对于 ODP 侧的连接池,假设 ODP 实例节点个数为 2,连接数则可以设置为 MIN=20/10/2=1,MAX=200/10/2=10。
另外,如果业务侧有大量使用 SCAN_ALL Hint 的场景,此时 QPS 在 ODP 侧将会被放大“分库数量”倍,最小、最大连接数也要相应乘以分库数量(考虑性能因素应该尽量规避 SCAN_ALL)。
计算模型
总结下来,我们可以得出连接数的计算模型:
应用侧:
最小连接数 =(QPS*请求平均耗时)/ 应用节点个数。
最大连接数 =(QPS*请求最大耗时)/ 应用节点个数。
ODP 侧:
最小连接数 =(QPS*请求平均耗时)/ ODP 节点个数。
最大连接数 = (QPS*请求最大耗时*2) / ODP 节点个数 (并且需要保证“最大连接数*分库数量*ODP 节点个数” 要小于数据库所支持的最大连接数量)。
在实际中,应用侧的请求耗时肯定要大于 ODP 侧的请求耗时,因为中间需要经过 ODP 处理,也就是说应用侧的请求耗时需要以应用记录为准,而 ODP 侧的则以 ODP 日志或者数据库日志记录为准。