获取开发用的SDK
可以在PIP的仓库中获取数据湖分析最新的开发SDK包,地址为Python SDK官方地址。
使用SDK提交Spark作业
- 获取用户的AccessKey,详情请参见获取AccessKey。
- 获取当前使用区的RegionId, 阿里云各区的RegionId可以参见地域和可用区。
- 确定执行任务的虚拟集群名称和JSON内容,您可以首先尝试在控制台提交作业, 其后根据下图确定输入和返回的内容。
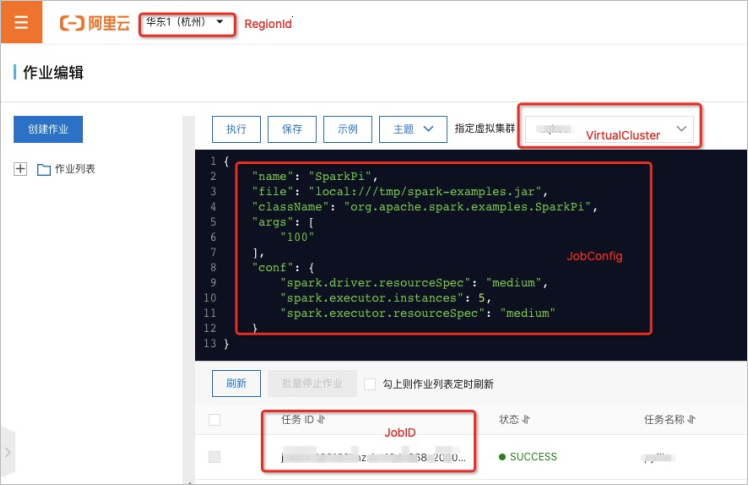 使用SDK提交作业的代码如下所示:
使用SDK提交作业的代码如下所示:def submit_spark_job(region: str, access_key_id: str, access_key_secret: str, cluster_name: str, job_config: str): """ 提交一个Spark job, 返回job_id :param region: 提交作业的区域ID :param access_key_id: 用户ak的ID :param access_key_secret: 用户ak的Secret :param cluster_name: 运行作业的Spark集群名称 :param job_config: 定义Spark作业的JSON字符串 :return: Spark任务的jobid :rtype: basestring :exception ClientException """ # 创建客户端 client = AcsClient(ak=access_key_id, secret=access_key_secret, region_id=region) # 初始化请求内容 request = SubmitSparkJobRequest.SubmitSparkJobRequest() request.set_VcName(cluster_name) request.set_ConfigJson(job_config) # 提交Job获取结果 response = client.do_action_with_exception(request) # 返回JobId r = json.loads(str(response, encoding='utf-8')) return r['JobId']注意 JobConfig是一个合法的JSON格式的String, 建议您手动在控制台执行成功一些小批量的作业, 然后通过SDK来自动化提交核心业务。