Serverless Presto是云原生数据湖团队基于Presto打造的交互式分析引擎,Presto开发的初衷就是为了解决使用Hive来进行在线分析速度太慢的问题,因此它采用全内存流水线化的执行引擎,相较于其它引擎会把中间数据落盘的执行方式,Presto在执行速度上有很大的优势,特别适合用来做Adhoc查询、BI分析、轻量级ETL等数据分析工作。
阿里云数据湖分析团队在Presto之上又进行了很多的优化,DLA支持了阿里云几乎所有的数据源比如AnalyticDB、TableStore等等;阿里云数据湖分析团队优化了Hive Connector,使得分析OSS数据时对OSS调用量大幅下降,从而提高性能且节省成本;DLA内置了企业级的权限控制体系,保护您的数据安全;内置了高可用的Coordinator方案,提高整体服务的可用性;DLA在Presto之上实现了MySQL接入协议,使得您可以使用任何兼容MySQL协议的工具来进行数据分析。
Serverless Presto的整体架构如下: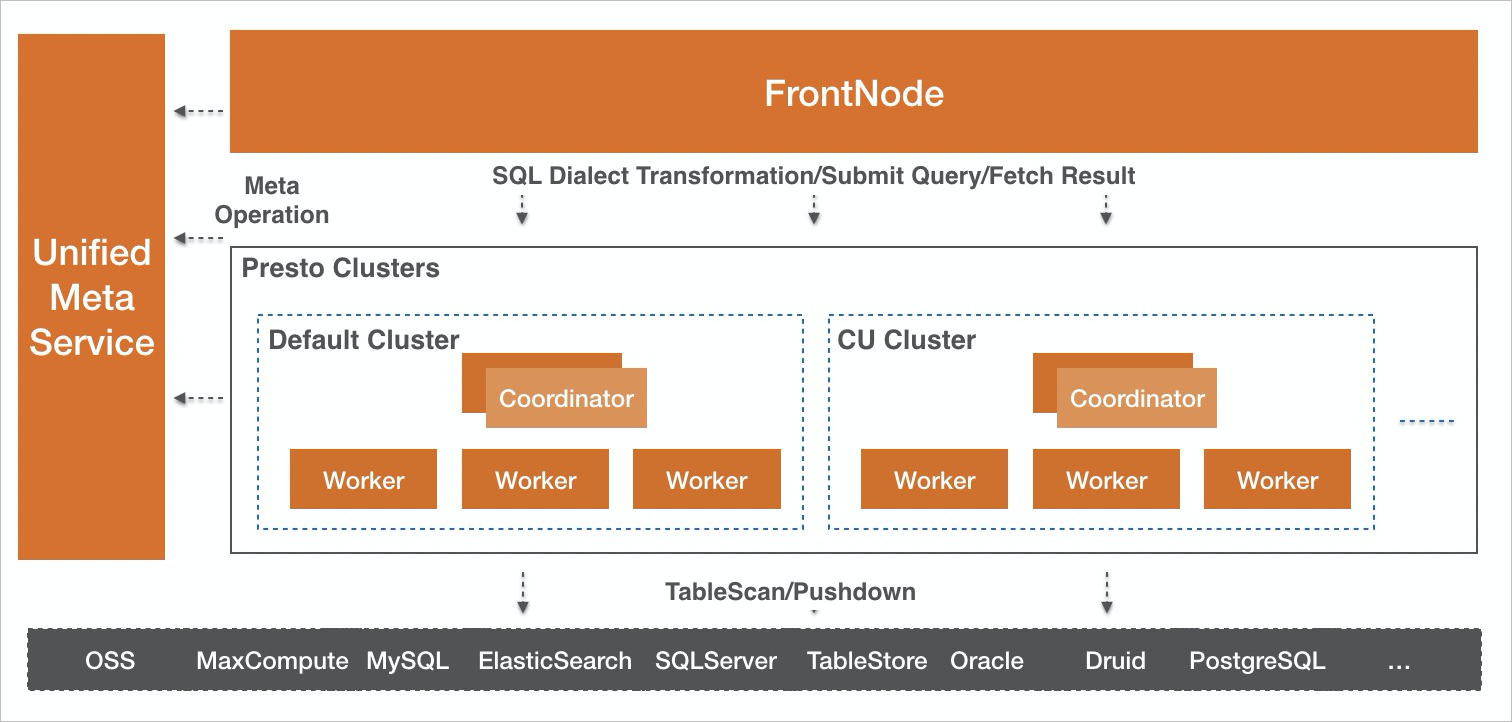
- FrontNode是用户访问的入口,它实现了MySQL协议,因此您使用任何兼容MySQL协议的客户端进行连接。
- Presto Clusters集群承担分析计算的职责。在每个Region,可以部署多个集群,一个是默认的按照扫描量计费的集群,其余的是按照CU付费的集群。
- 您可以阅读文档计费概述来学习几种计费方式的差异。
- 您可以阅读文档扫描量版本与CU版本的差异来学习扫描量版本和CU版本的具体功能差异。
- 您可以阅读文档DLA Presto CU版本快速入门来学习如何开通、使用DLA Presto的CU版本。
- 您可以阅读SQL参考文档学习如何创建库和表、数据查询、权限控制等其它SQL语法。每种数据源创建库、表的选项稍有不同,可以阅读连接数据源下面的文档来查看建每种数据源库表的具体写法。
- DLA的Presto Clusters集群是兼容社区Presto的,关于函数的具体定义可以参考社区文档。
- Presto Clusters集群下面可以接入各种数据源。
- 您可以阅读连接数据源下面的文档来学习如何连接到各种数据源。