本次测试采用3种不同的测试场景,针对开源自建的Hadoop+Spark集群与阿里云云原生数据湖分析DLA Spark在执行Terasort基准测试的性能做了对比分析。本文档主要展示了开源自建Spark和DLA Spark在3种测试场景下的测试结果及性能对比分析。
1 TB测试数据下DLA Spark+OSS与自建Hadoop+Spark集群性能对比结果
| 集群类型 | 运行Terasort基准测试集耗时(h) | 费用价格(元) |
|---|---|---|
| DLA Spark+OSS | 0.701 | 577.42 |
| 自建Hadoop+Spark | 0.733 | 10543.04 |
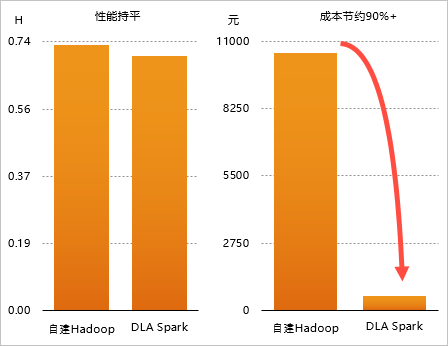
通过上述耗时和价格对比结果可以看出,作业性能上DLA Spark跟自建Spark基本持平,但是性价比差异非常大,DLA Spark能节约90%的成本,会有9~10倍的性价比提升。对于中小客户来说,业务比较简单,集群的使用空闲率较高,使用DLA Spark会极大的降低成本。
需要强调的是,DLA Spark完全按需使用存储和计算资源,对OSS访问实现了深度定制优化,性能相比于优化前提升1倍左右,与Spark访问HDFS性能持平。
10 TB测试数据下DLA Spark+OSS与自建Hadoop+Spark性能对比结果
| 集群类型 | 运行Terasort基准测试集耗时(h) | 价格(元) |
|---|---|---|
| DLA Spark+OSS | 5.2 | 10989.4 |
| 自建Hadoop+Spark | 13.9 | 23660.24 |
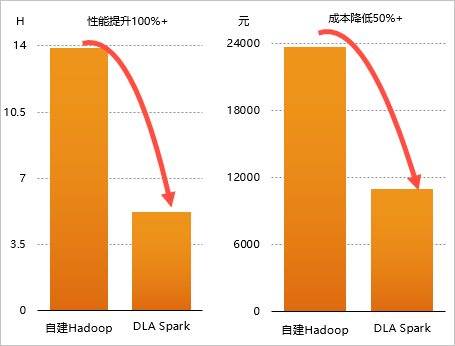
通过上述耗时和价格对比结果可以看出,性能上DLA Spark提升了1倍,成本反而降低了一半,性价比提升4倍。
在分析性能时发现,在10 TB场景下,本地盘的存储和shuffle之间会有IO带宽上的明显争抢,而Serverless Spark计算节点自带essd云盘,与shuffle盘完全独立,能较高的提升性能。
1 TB测试数据下DLA Spark+用户自建Hadoop集群与自建Hadoop+Spark性能对比结果
| 集群类型 | 运行Terasort基准测试集耗时(min) |
|---|---|
| DLA Spark+OSS | 43.5 |
| 自建Hadoop+Spark | 44.8 |
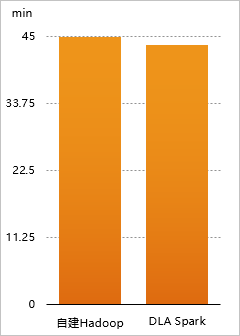
您可以将自建Hadoop和DLA Spark混合使用,自建Hadoop集群在高峰期需要更多的计算资源。DLA Spark可以直接跟您的VPC网络打通,直接使用内网的带宽,计算性能相对于本地计算并没有降低。DLA Spark完全弹性的模式,1分钟内可以拉起500~1000个计算节点,可以很好满足您对弹性计算的需求。