一、模板说明
通过提供通用机器学习模板,展示完整的数据收集、特征工程、模型选择和训练、模型评估、模型部署和应用以及模型复用的一系列算子的使用方法,使用户能够高效构建准确的联邦学习模型。
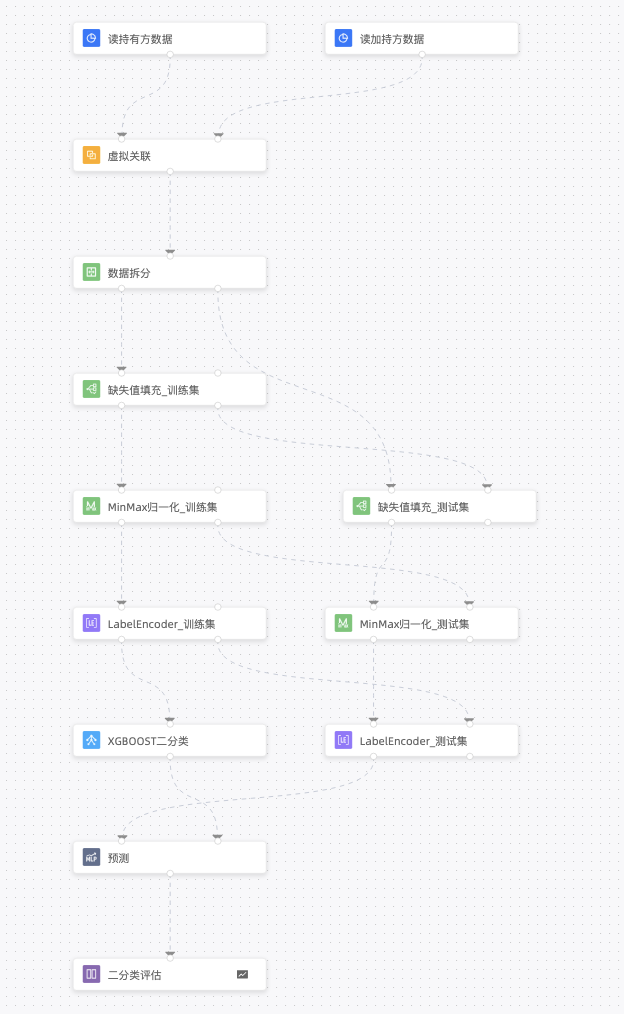
二、使用步骤
通过提供通用机器学习模板,展示完整的数据收集、特征工程、模型选择和训练、模型评估、模型部署和应用以及模型复用的一系列算子的使用方法,使用户能够高效构建准确的联邦学习模型。
step 1 联邦数据输入:收集和准备原始数据,包括数据输入和虚拟关联,使得用户能够在形式上以单机的方式使用联邦学习双方的数据。
note: 所有的数据均保存在持有方本地,本身绝对保密。虚拟关联仅是在形式上模拟为同一份数据,以方便用户搭建顺利。
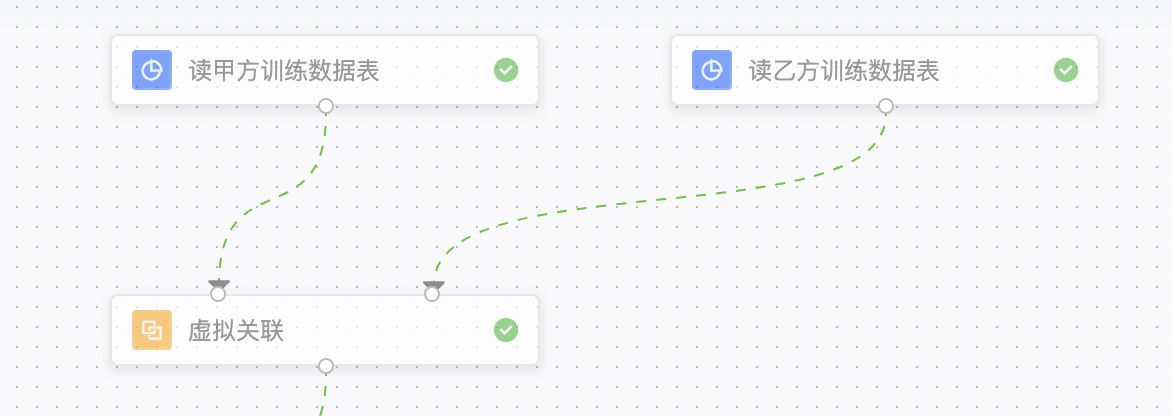
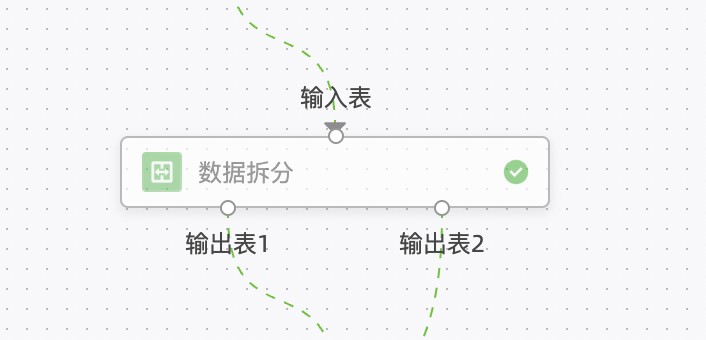
step 2 数据拆分:将数据拆分为训练集和测试集,用于验证模型的各项指标数据。
note:在模板中,选择了拆分比例80%,即80%数据用于训练(输出表1),20%数据用于测试(输出表2)。用户可自行调整需求。
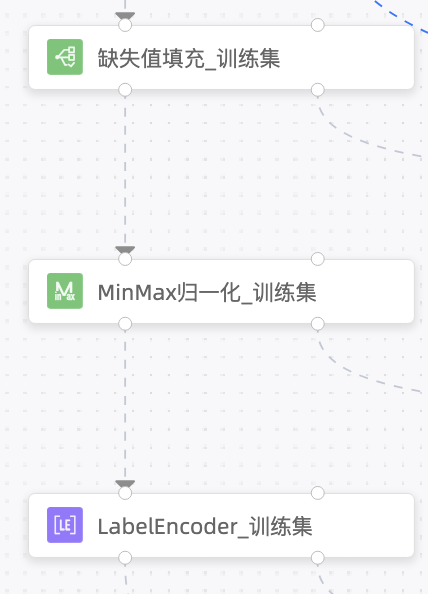
step 3 训练侧特征工程:选择和提取有用的特征,包括特征选择、特征变换、特征抽取和特征组合等。其中,对于Category特征和Numeric特征,均有对应的处理方案,详见组件说明。特征工程的配置可输出,供预测和评估流程使用。
step 4 测试侧特征工程:选择和提取有用的特征,包括特征选择、特征变换、特征抽取和特征组合等。其中,对于Category特征和Numeric特征,均有对应的处理方案,详见组件说明。特征工程的配置由输入的配置文件确定,用户也可自行设定。
step 5 模型训练和预测:选择合适的算法和模型,训练模型并进行调参和优化。目前联邦学习模型可以选择XGBoost、Logistic Regression、DNN等。
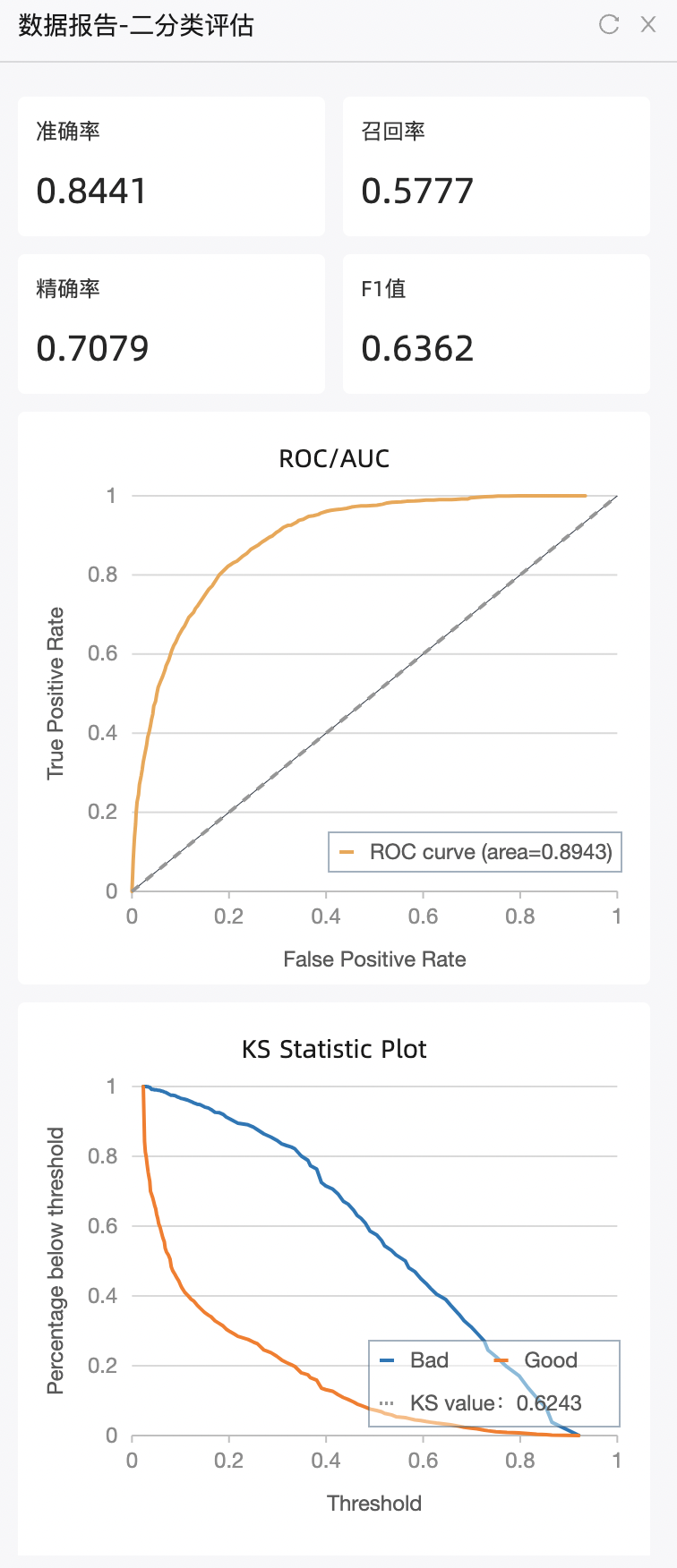
step 6 模型评估:使用各种评估指标和技术对模型进行评估,用户可以自行使用交叉验证等方法,测试不同数据集的混淆矩阵、AUC、KS等各项指标。详见组件说明。

三、名词解释
Category特征:是指数据集中的离散型变量,其取值通常为一个有限的集合,并且这些取值之间没有大小或序的关系。例如,性别、婚姻状况、职业、城市等都是Category类特征。在DataTrust中用String标识。
Numeric特征:取值通常是一个数值或一段数值区间,其取值可以是任意实数,并且具有大小和顺序的关系。例如年龄、收入等都是Numeric特征。其中,整型Numeric特征用BIGINT标识,浮点型Numeric特征用DOUBLE标识。
交叉验证:在交叉验证中,数据集被划分为训练集和验证集两部分,模型基于训练集进行训练,然后用验证集来评估模型的性能。这种方法可以有效地评估模型的泛化能力,并减少因样本随机性带来的影响。
混淆矩阵:评估分类模型性能的一种重要工具,可以用来计算模型的准确率、精确率、召回率、F1得分等性能指标。其中,准确率指模型正确预测的样本数占总体样本数的比例;精确率指预测为正例的样本中实际为正例的比例;召回率指实际为正例的样本中被正确预测为正例的比例;F1得分是精确率和召回率的调和平均数。
AUC:用于评估二分类模型性能的一种常用指标,取值范围在0.5到1之间,AUC越大表示模型性能越好。
KS值:是用于衡量二分类模型区分度的指标,常用于评估信用风险、反欺诈等领域。KS值的取值范围在0到1之间,KS值越大,表示模型的区分度越好,分类效果越好。通常将KS值大于0.2视为模型的分类效果良好,KS值小于0.2则需要进一步优化模型。