云数据库 SelectDB 版是基于Apache Doris研发的现代化实时数仓服务,采用全新的云原生存算分离架构。本文为您介绍云数据库 SelectDB 版的产品架构及基本原理。
架构图
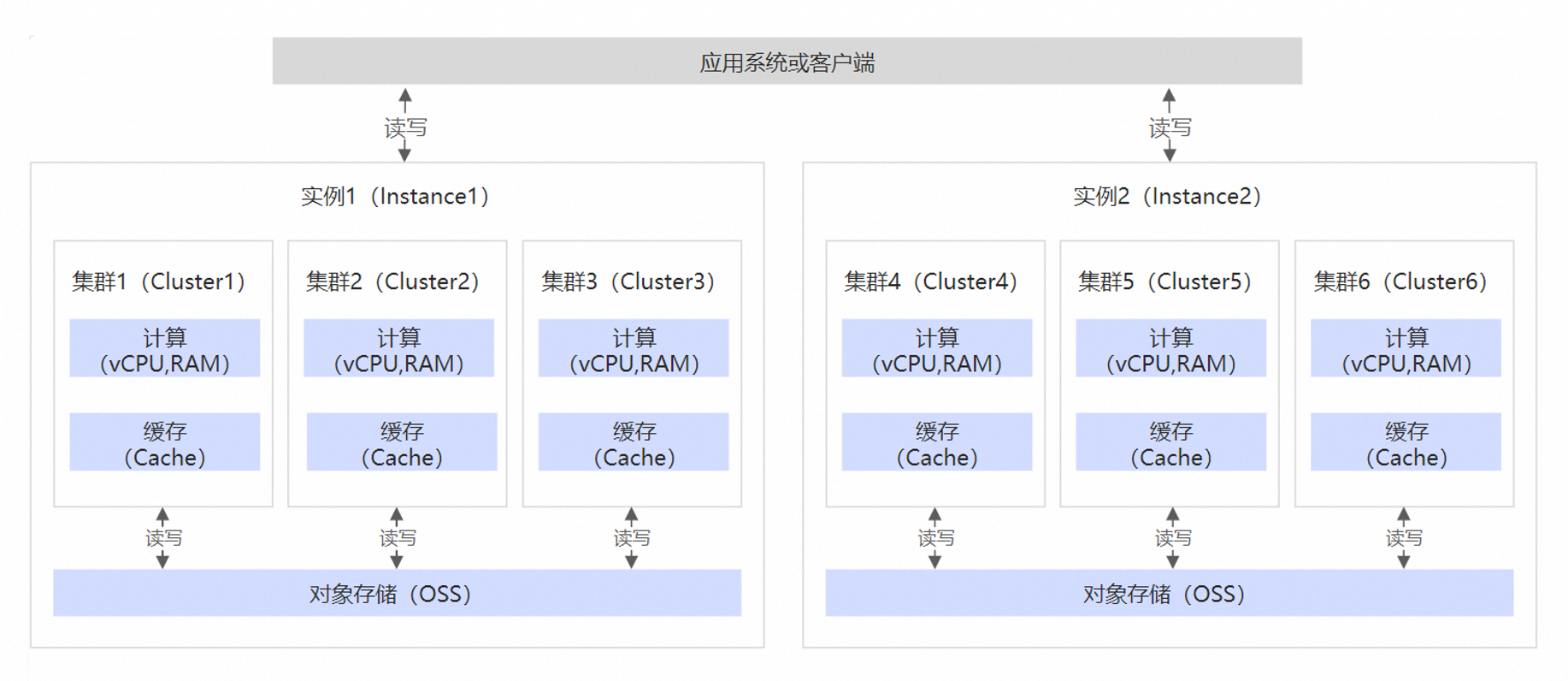
组件说明
应用系统或客户端
应用系统或客户端是您访问云数据库 SelectDB 版的产品或工具。由于云数据库 SelectDB 版兼容MySQL连接协议和标准SQL语法,因此MySQL生态中的命令行工具、JDBC/ODBC驱动以及可视化工具等,均可连接访问云数据库 SelectDB 版的实例。
为了减少网络延时和不稳定的影响,建议应用程序或客户端与云数据库 SelectDB 版实例部署在相同地域。
实例
云数据库 SelectDB 版 的实例是购买和使用数据库服务的基本单元。在购买云数据库 SelectDB 版 的实例后,实例以及相关集群的资源归属于您。云数据库 SelectDB 版采用云原生存算分离架构,包含实例入口(负责接收请求,包含一组FE节点)、集群(负责实际请求执行的分布式系统,包含一组BE节点)、存储(对象存储OSS)等组件。其中实例入口由云数据库 SelectDB 版托管并按需伸缩,您无需管理。云数据库 SelectDB 版的多实例之间的资源是完全物理隔离的,可用于满足完全独立的或敏感性差别较大的业务场景。
在使用云数据库 SelectDB 版实例进行读写操作时,主体流程如下:
写入请求:您可通过云数据库 SelectDB 版提供的写入接口或者已有的导入工具,向云数据库 SelectDB 版发起写入请求。实例入口接收到请求后,根据您选择或者默认设置将请求重定向给目标集群。目标集群具体处理写入请求,其将数据写入对象存储及缓存中,在对象存储完成持久化后,返回成功提示。
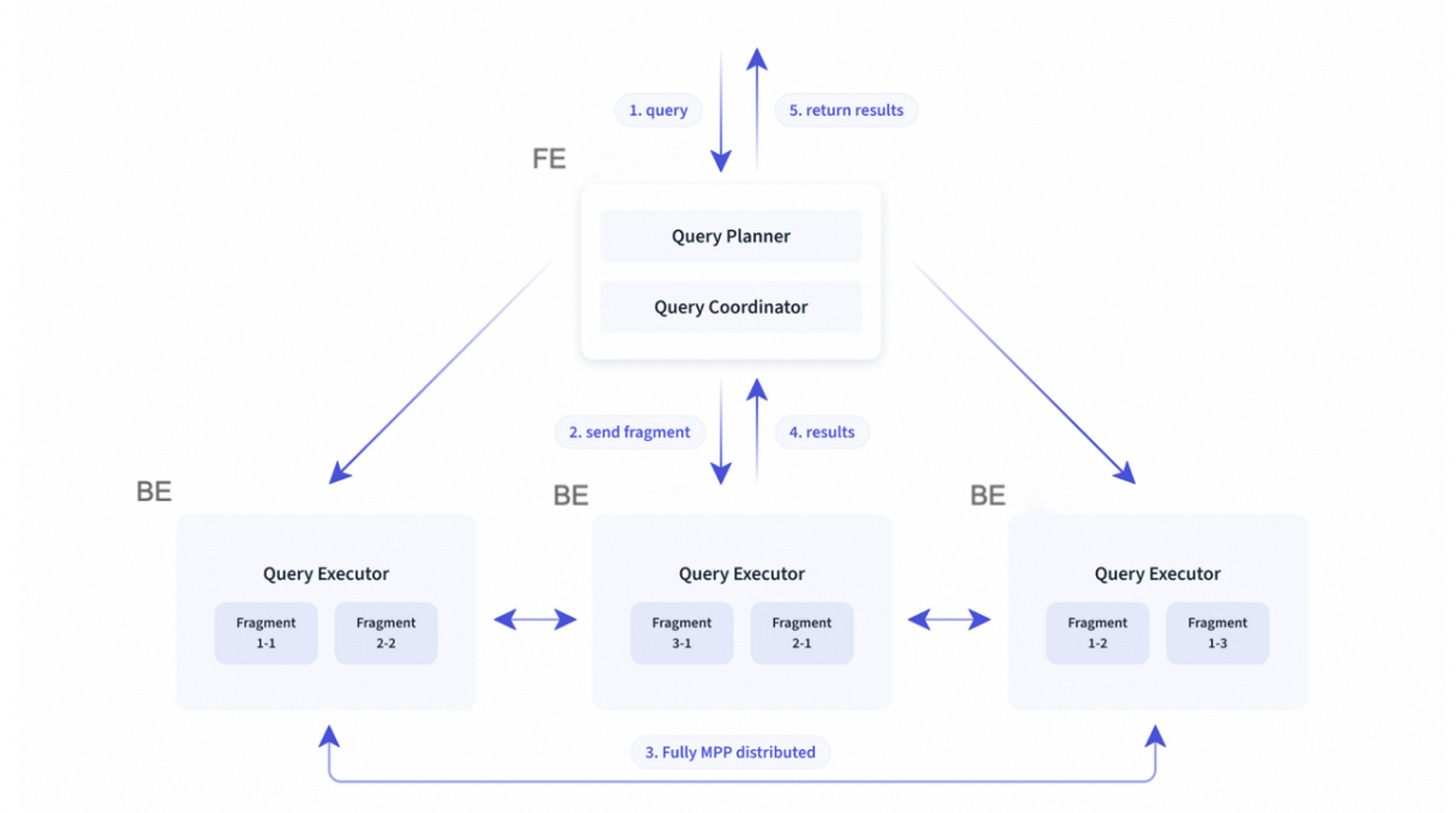
查询请求:您可通过执行SQL向云数据库 SelectDB 版发起查询请求。实例入口接收到查询请求后,首先会对请求的SQL进行解析,然后智能优化器对SQL进行优化,产出高效的查询执行计划,最后将请求转发给目标集群。目标集群对查询请求进行大规模并发调度执行(Massively Parallel Processing),查询按需读取缓存或对象存储中的数据,完成后通过MySQL协议将结果返回。集群在查询处理过程中,采用了Pipeline执行框架、索引技术、缓存技术、向量化技术等技术,使得查询速度加快,让您体验到云数据库 SelectDB 版更好的数据分析性能。以下为云数据库 SelectDB 版处理一个查询请求的过程图。
集群
云数据库 SelectDB 版的集群是包含一个或多个BE节点的分布式系统,每个节点包含计算资源和缓存资源。由于存算分离架构中对象存储访问较慢,所以引入缓存用以加速数据访问。云数据库 SelectDB 版支持内存、硬盘等多级缓存机制。集群支持灵活的弹性伸缩能力,伸缩过程会进行缓存的预热与迁移,尽可能为您提供平滑的分析体验。
云数据库 SelectDB 版支持多集群架构,一个实例中可以包含多个集群,类似经典分布式架构中的计算队列、计算组。同一实例中的多个集群具有如下特性:
数据共享:多集群共享底层对象存储,均可访问底层数据,避免了冗余数据存储。
计算隔离:多集群间的计算与缓存资源是完全独立的,可用于隔离不同的工作负载。每个集群可以按需购买不同规格的计算资源和存储资源,并根据自身访问规律进行数据缓存。
多读多写:多集群在数据读写方面具有独立对等的特性,能够并行写入数据。一旦数据提交生效,所有集群均可立即查询到最新的数据。
基于上述特性,多集群通常用于实现读写隔离、在线与离线业务隔离以及生产与测试环境隔离等场景。
存储
云数据库 SelectDB 版采用高可靠、低成本的对象存储OSS作为存储系统,用于持久化保存数据。基于对象存储本身的高可靠性,云数据库 SelectDB 版无需在分布式数仓系统中维护数据副本。此外,基于对象存储OSS的低成本特性,SelectDB的单位存储成本相比传统数仓可降低90%以上。
云数据库 SelectDB 版的存储资源无需预设大小,其采用按量付费的计费方式,并支持使用存储资源包进行抵扣,从而进一步降低了存储成本。
为了提供更好的分析性能,云数据库 SelectDB 版对存储和计算进行了深度结合设计,具体体现在以下几个方面。
数组组织:为提升数据的访问效率,云数据库 SelectDB 版对底层数据组织进行了精致的设计。
数据分区:数据按照时间段或Hash值进行划分打散,以充分利用分布式集群的处理能力,同时有利于查询时数据裁剪。
支持行列混合存储:默认的列式存储可满足海量数据的高效分析,按需开启的行式存储可支持高性能的点查询。
丰富的索引能力:可结合过滤条件精准定位数据,数量级提升查询性能。
数据模型:云数据库 SelectDB 版对于不同的数据分析场景,提供了不同的数据模型。
主键模型(Unique模型):适用于对数据有唯一主键要求或高效更新要求的场景。例如电商订单、用户属性信息等数据分析场景。
明细模型(Duplicate模型):适用于保留所有原始数据记录的场景。例如日志、账单等明细数据分析场景。
聚合模型(Aggregate模型):适用于通过预聚合提升查询性能的聚合统计场景。例如网站流量分析、定制化报表等数据分析场景。
外部生态
云数据库 SelectDB 版支持与周边数据生态中的数据源及可视化工具进行集成,显著提升数据分析的便捷性。