一、组件说明
横向逻辑回归通过将线性回归模型的输出通过Sigmoid函数进行映射,将连续的预测值转换为概率值。Sigmoid函数具有“S”形状,可以将任意实数值映射为0和1之间的概率值,表示样本属于正例的概率。
横向逻辑回归的训练过程是利用最大似然估计方法,寻找能够最大化训练数据集中样本类别之间的差异性的模型参数。
在二分类问题中,横向逻辑回归将输入数据特征映射到一个二元分类输出,即预测样本属于正例或负例的概率。
组件截图
二、参数说明
字段设置
参数名称 | 参数说明 |
标签字段 | 用于训练的标签字段,数值类型,单选。 |
正样本标签值 | 正样本标签的原值或编码值,如:>50K。 |
特征字段 | 用于训练的特征字段,数值类型,多选。注意:正常情况下请检查,在特征字段中不要勾选标签字段。 |
输入特征为KV格式 | 目前DataTrust支持KV格式的特征输入(即LIBSVM格式)。使用时,数据格式如下,其中key的下标应从1开始,value应均为数值: |
正样本标签值填写
字段数据类型 | 是否编码 | 是否连接配置表 | 正样本标签值 |
字符类型 | 是 | 是 | 原值 |
是 | 否 | 编码值 | |
数值类型 | 否 | 否 | 原值 |
否 | 是 | 原值 | |
是 | 是 | 原值 | |
是 | 否 | 编码值 |

参数设置
参数名称 | 参数英文名称 | 参数说明 |
全局迭代轮数 | epochs | 全局模型的最大迭代次数 |
隐私开销 | epsilon | 联邦学习中,差分隐私的隐私开销,数值越大,添加的噪声越小,隐私保护越弱,则越精确,训练效果越好;数值越小,隐私保护强度越强,则单样本噪音值越大,获取统计特征越困难。 |
裁剪阈值 | clipping_threshold | 差分隐私裁剪阈值,用于截断模型参数。裁剪阈值越大,添加的噪声越大,隐私保护越强。适当调整阈值大小,可在保护隐私情况下,提升模型收敛速度。 |
(使用/加持方) 批处理大小 | batch_size | 每个小批次的样本数量。batch_size的大小会影响模型的训练速度和泛化能力,通常情况下,较小的batch_size可以更快地收敛,但可能会导致模型过拟合;较大的batch_size会更稳定,但收敛速度较慢。 |
(使用/加持方) 最大迭代轮数 | local_epochs | 本地模型样本的最大迭代次数。各方本地迭代次数可不同。 |
(使用/加持方) 学习率 | learning_rate | 学习率,控制每轮迭代权重的缩小程度,适当调整可以加速模型收敛但也可能使模型过拟合。 |
(使用/加持方) 最小损失 | min_loss | 训练到这个loss后,将提前停止。 |
(使用/加持方) 权重衰减项 | weight_decay | 值越大,衰减越大,取值为[0, 1)之间的浮点数。 |
(使用/加持方) 正则化项 | penalty | 权重衰减项为L1正则或L2正则。 |
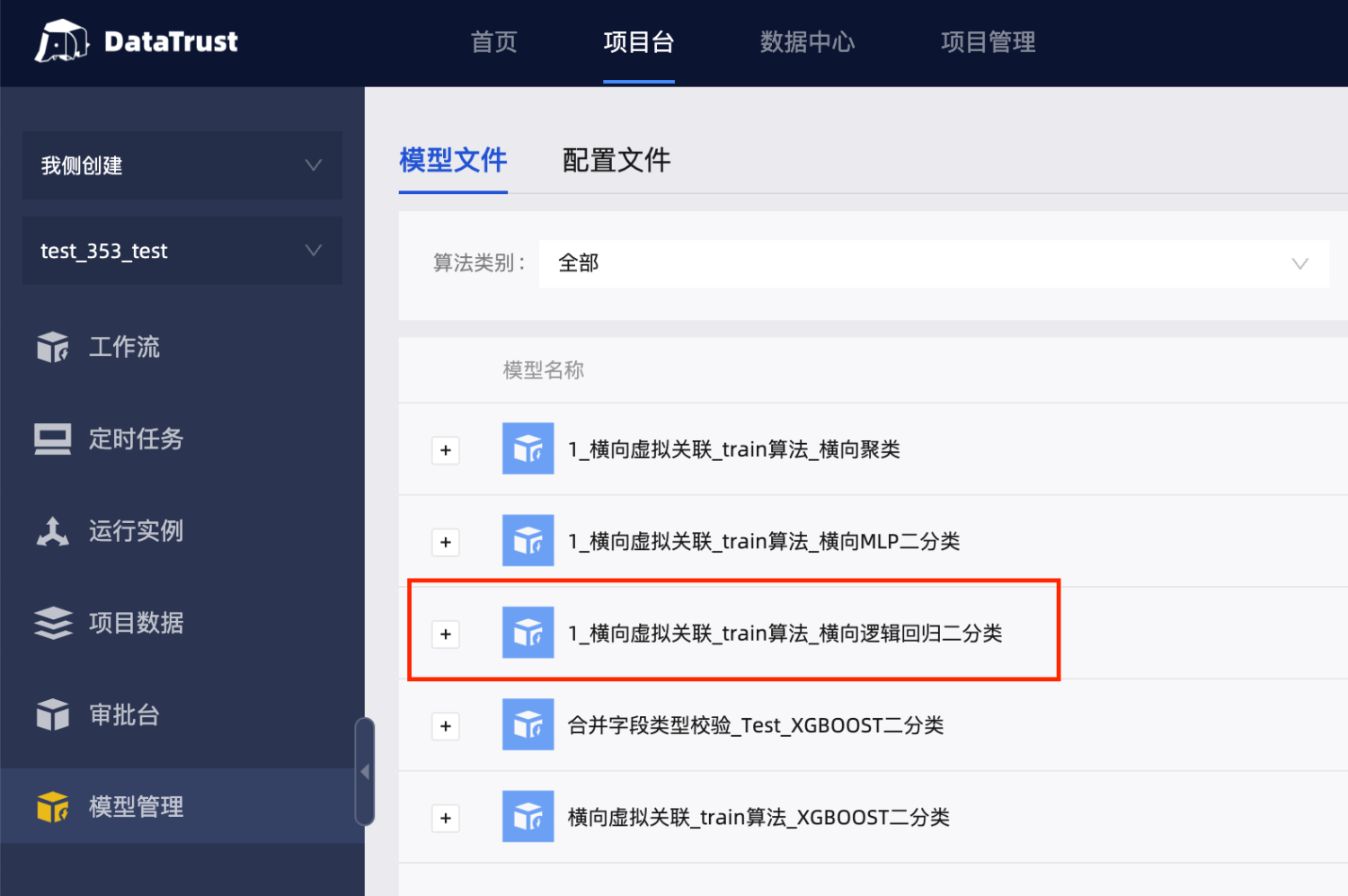
训练成功后的模型保存
训练成功后,双方本地均保存有最终的全局模型。该全局模型支持双方进行单方预测、评估使用。训练成功的模型保存在【项目台】-【模型管理】-【模型文件】中,保存名称为${工作流名称}_${建模组件名称}。例如,本项目中有成功建模的任务名为“1_横向虚拟关联_train算法”,其中有建模组件名字为“横向逻辑回归二分类”,则模型名字为“1_横向虚拟关联_train算法_横向逻辑回归二分类”,如下图所示: