在轨迹分析场景中,通常需要对轨迹点进行计算和处理,得到轨迹规律和运动趋势。如果业务中存在大量的冗余轨迹点,可能会导致计算成本的增加。您可以通过Lindorm时空函数完成轨迹抽稀,过滤掉冗余的轨迹点,提取特征数据并保留轨迹规律,同时降低计算成本。
场景描述
随着移动互联网的发展和移动终端的普及,我们日常生活中产生了大量的移动对象轨迹数据,这些数据的存储成为了新的挑战。为应对这一挑战,Lindorm宽表引擎提供了空间数据类型和Ganos服务,支持将位置信息以POINT空间数据类型、FLOAT经纬度形式存储在宽表引擎中,您还可以使用时空函数或通过构建索引,优化查询性能。
以下是一个轨迹分析场景中,使用时空函数优化查询的示例:
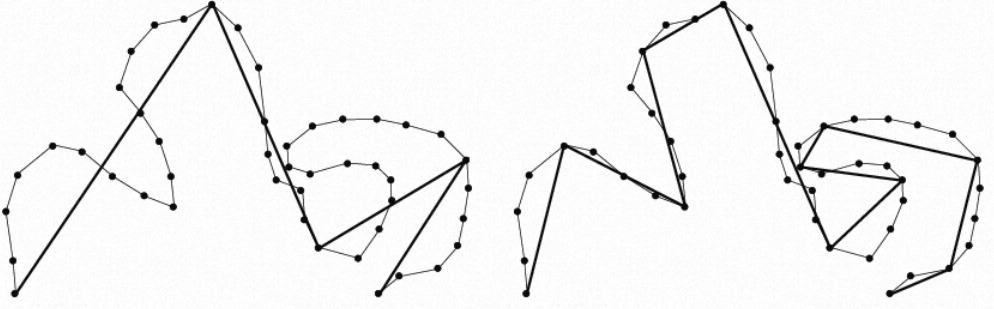
某物联网平台客户使用Lindorm存储轨迹数据,需要实时将轨迹显示在大屏中,为减少前端渲染计算量,需要按照指定规则,根据不同的精度需求对轨迹进行抽稀,抽稀前后结果如下图所示。
技术实现
Lindorm Ganos时空服务提供了ST_Resample聚合函数,可以通过指定抽稀算法实现不同效果的轨迹抽稀,减少数据传输和前端渲染的计算量。
ST_Resample函数共支持三种空间抽稀(降采样)算法:
Visvalingam-Whyatt算法:指定容差,递归解出轨迹上连续三点组成的三角形的面积最大值,保留所有面积大于容差的点。
Douglas-Peucker (DP) 算法:指定容差,递归解出两点连线与两点之间的各个顶点的垂直距离最大值,保留所有垂直距离大于容差的点。
Topology Preserving DP算法:保留轨迹线串拓扑结构的Douglas-Peucker算法。
ST_Resample聚合函数也支持按照时间间隔来抽稀,详细介绍,请参见ST_Resample。
前提条件
已将客户端IP地址添加至Lindorm白名单。如何添加,请参见设置白名单。
已开通Lindorm Ganos时空服务。如何开通,请参见开通时空服务(免费)。
步骤一:建表并写入测试数据
创建表gps_points,包含三个列:设备ID列account_id、数据采集时间列collect_time、POINT类型轨迹点列gps_point。
CREATE TABLE gps_points (account_id VARCHAR, collect_time TIMESTAMP, gps_point GEOMETRY(POINT), PRIMARY KEY(account_id, collect_time));写入测试数据。
INSERT INTO gps_points(account_id, collect_time, gps_point) VALUES('001', '2023-11-10 11:00:30', ST_MakePoint(113.665431, 34.773)), ('001', '2023-11-10 11:00:31', ST_MakePoint(113.665432, 34.773)), ('001', '2023-11-10 11:00:32', ST_MakePoint(113.665433, 34.773)), ('001', '2023-11-10 11:00:33', ST_MakePoint(113.665434, 34.774));
步骤二:抽稀查询
使用Ganos聚合函数ST_Resample,可以实现仅通过一条SQL语句就获取到抽稀结果。
以下示例指定了轨迹点对象列 (gps_point)、时间列 (collect_time),获取account_id为001的设备在指定时间段内采集到的轨迹点,并指定抽稀算法和降采样距离阈值。
SELECT ST_Resample(gps_point, collect_time,'{"downsample_distance": 0.0001, "simplifier": "vw"}') as resampled_traj FROM gps_points WHERE collect_time >= '2023-11-10 00:00:00' and collect_time <= '2023-11-11 00:00:00' and account_id='001';返回结果如下:
+---------------------------------------------------------+
| resampled_traj |
+---------------------------------------------------------+
| [{"x":113.665431,"y":34.773,"t":"2023-11-10 |
| 11:00:30.0"},{"x":113.665434,"y":34.774,"t":"2023-11-10 |
| 11:00:33.0"}] |
+---------------------------------------------------------+返回值为降采样后按时间排序的轨迹点序列,类型为STRING,格式为[{\"x\":经度,\"y\":纬度,\"t\":时间}, {\"x\":经度,\"y\":纬度,\"t\":时间}, ...]。
性能表现
当表中的行数达到10亿级别,查询的轨迹时间范围可能从几小时到数天不等。
下表统计了数据集行数为10亿以上时,不同时间维度,相同时间范围内使用ST_Resample函数和不使用ST_Resample函数的返回点数:
查询时间范围 | 使用ST_Resample函数 | 不使用ST_Resample函数 |
1小时 | 9 | 405 |
1天 | 37 | 829 |
10天 | 118 | 8539 |
可以看出,当查询数据范围较大时,使用ST_Resample函数进行查询时返回点数显著减少。对比不使用ST_Resample函数,使用ST_Resample函数后可以减少数据计算成本,简化数据计算方式。