本文主要介绍云数据库 SelectDB 版中的BloomFilter索引以及使用时的注意事项。
背景信息
BloomFilter是由Bloom在1970年提出的一种多哈希函数映射的快速查找算法。通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合。
BloomFilter有以下特点:
空间效率高的概率型数据结构,用来检查一个元素是否在一个集合中。
对于一个检测元素是否存在的调用请求,BloomFilter会告诉调用者两个结果之一:可能存在或者一定不存在。
缺点是存在误判的,告诉您可能存在,但不一定真实存在。
BloomFilter是由一个超长的二进制位数组和一系列的哈希函数组成。二进制位数组初始全部为0,当给定一个待查询的元素时,这个元素会被一系列哈希函数计算映射出一系列的值,所有的值在位数组的偏移量处置为1。
下图所示出一个m=18,k=3(m是该Bit数组的大小,k是Hash函数的个数)的BloomFilter示例。集合中的x、y、z三个元素通过3个不同的哈希函数散列到位数组中。当查询元素w时,通过哈希函数计算之后因为有一个比特为0,因此w不在该集合中。
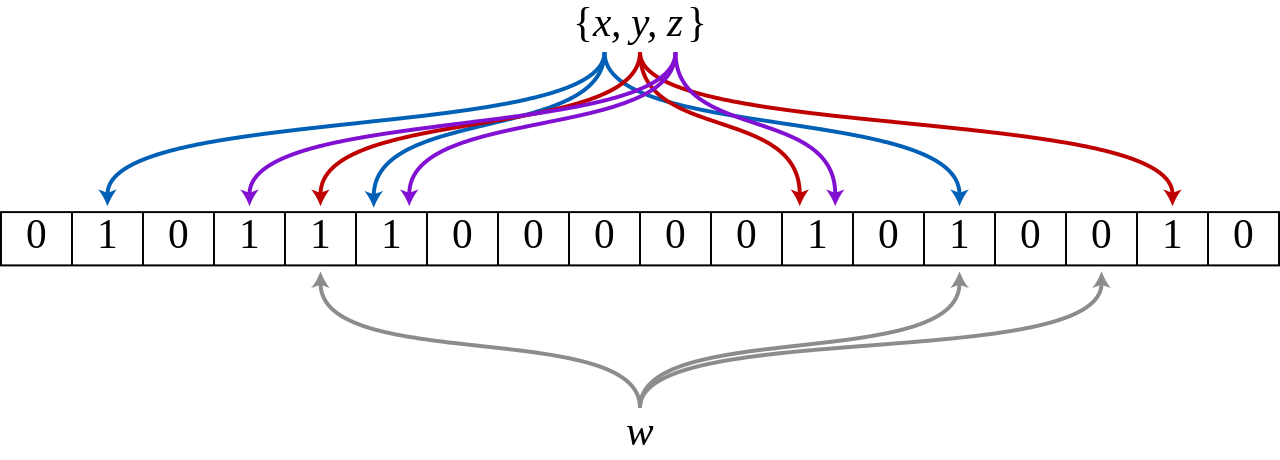
如何判断某个元素是否在集合中,同样是这个元素经过哈希函数计算后得到所有的偏移位置,若这些位置全都为1,则判断这个元素在这个集合中,若有一个不为1,则判断这个元素不在这个集合中。
BloomFilter索引管理
创建索引
BloomFilter本质上是一种位图结构,用于快速的判断一个给定的值是否在一个集合中。这种判断会产生小概率的误判。即如果返回false,则一定不在这个集合内;而如果返回true,则有可能在这个集合内。
BloomFilter索引是以Block为粒度创建的。每个Block中,指定列的值作为一个集合生成一个BloomFilter索引条目,用于在查询是快速过滤不满足条件的数据。
云数据库 SelectDB 版的BloomFilter索引可以通过建表的时候指定,或者通过表的ALTER操作来完成。创建BloomFilter索引,是通过在建表语句的PROPERTIES里加上"bloom_filter_columns"="k1,k2,k3"这个配置属性来进行的。其中,k1,k2,k3是要创建的BloomFilter索引的Key列名称。
例如对表sale_detail_bloom创建BloomFilter索引saler_id、category_id。
CREATE TABLE IF NOT EXISTS sale_detail_bloom(
sale_date date NOT NULL COMMENT "销售时间",
customer_id int NOT NULL COMMENT "客户编号",
saler_id int NOT NULL COMMENT "销售员",
sku_id int NOT NULL COMMENT "商品编号",
category_id int NOT NULL COMMENT "商品分类",
sale_count int NOT NULL COMMENT "销售数量",
sale_price DECIMAL(12,2) NOT NULL COMMENT "单价",
sale_amt DECIMAL(20,2) COMMENT "销售总金额"
)
Duplicate KEY(sale_date, customer_id, saler_id, sku_id, category_id)
distributed BY hash(customer_id) buckets 3
PROPERTIES("bloom_filter_columns"="saler_id, category_id");查看索引
查看表中建立的BloomFilter索引,语法如下。
SHOW CREATE TABLE <table_name>;以sale_detail_bloom表为例,示例如下。
SHOW CREATE TABLE sale_detail_bloom;查询结果如下。
+-------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| sale_detail_bloom | CREATE TABLE `sale_detail_bloom` (
`sale_date` datev2 NOT NULL COMMENT '销售时间',
`customer_id` int(11) NOT NULL COMMENT '客户编号',
`saler_id` int(11) NOT NULL COMMENT '销售员',
`sku_id` int(11) NOT NULL COMMENT '商品编号',
`category_id` int(11) NOT NULL COMMENT '商品分类',
`sale_count` int(11) NOT NULL COMMENT '销售数量',
`sale_price` decimalv3(12, 2) NOT NULL COMMENT '单价',
`sale_amt` decimalv3(20, 2) NULL COMMENT '销售总金额'
) ENGINE=OLAP
DUPLICATE KEY(`sale_date`, `customer_id`, `saler_id`, `sku_id`, `category_id`)
COMMENT 'OLAP'
DISTRIBUTED BY HASH(`customer_id`) BUCKETS 3
PROPERTIES (
"bloom_filter_columns" = "category_id, saler_id",
"light_schema_change" = "true"
); |
+-------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.03 sec)修改索引
修改索引即为修改表的bloom_filter_columns属性,语法如下。
ALTER TABLE <db.table_name> SET ("bloom_filter_columns" = "k1,k3");删除索引
删除索引即为删除索引列中bloom_filter_columns属性,语法如下。
ALTER TABLE <db.table_name> SET ("bloom_filter_columns" = "");查看索引变更进度
创建、修改、删除索引是异步过程,可通过命令查看任务进度,语法如下。
SHOW ALTER TABLE COLUMN;BloomFilter使用场景
满足以下几个条件时可以考虑对某列建立BloomFilter索引。
非前缀过滤时。
查询会根据该列高频过滤,而且查询条件大多是
in和=过滤。不同于Bitmap,BloomFilter适用于高基数列,比如UserID。因为如果创建在低基数的列上,比如“性别”列,则每个Block几乎都会包含所有取值,导致BloomFilter索引失去意义。
示例
要查找一个占用100 Byte存储空间大小的短行,一个64 KB的HFile数据块应该包含(64*1024)/100=655.53行,大约700行。如果仅能在整个数据块的起始行键上建立索引,那么它是无法提供细粒度的索引信息的。因为要查找的行数据可能会落在该数据块的行区间上,可能行数据没在该数据块上,也可能是表中根本就不存在该行数据,或者是行数据在另一个HFile里,甚至在MemStore里。以上这几种情况,都会导致从磁盘读取数据块时带来额外的IO开销,也会滥用数据块的缓存,当面对一个巨大的数据集且处于高并发读时,会严重影响性能。
因此,HBase提供了布隆过滤器,它允许您对存储在每个数据块的数据做一个反向测试。当某行被请求时,通过布隆过滤器先检查该行是否不在这个数据块,布隆过滤器确定回答该行不在,或者回答它不知道。这就是我们称的反向测试。布隆过滤器也可以应用到行里的单元上,当访问某列标识符时可以先使用同样的反向测试。
但布隆过滤器是有代价的,存储这个额外的索引层次会占用额外的空间。布隆过滤器随着它们的索引对象数据增长而增长,所以行级布隆过滤器比列标识符级布隆过滤器占用空间要少。当空间不是问题时,它们可以帮助您充分利用系统的性能潜力。
SelectDB的BloomFilter索引可以通过建表的时候指定,或者通过表的ALTER操作来完成。
BloomFilter索引也是以Block为粒度创建的。每个Block中,指定列的值作为一个集合生成一个BloomFilter索引条目,用于在查询时快速过滤不满足条件的数据。
注意事项
列类型为Tinyint、Float、Double不支持创建BloomFilter索引。
Bloom Filter索引只对
in和=过滤查询有加速效果。查看某个查询是否命中了BloomFilter索引,可以通过查询的Profile信息查看。