异常应急功能展示了数据库集群的性能监控数据,以及最近 3 天内发生或正在发生的异常事件。您可以通过该功能快速获取集群的健康状态,并在异常事件发生时,进行根因分析,定位问题原因。
查看性能监控数据
登录 OceanBase 管理控制台。
在左侧导航栏,选择 自治服务 > 诊断中心。
在 实例详情 区域,单击目标实例名称。
系统自动跳转到诊断中心。
在左侧导航栏,单击 异常应急。
在 性能监控 区域,查看 CPU 使用率、租户 CPU 使用率、请求等待队列耗时 等监控指标的数据。
系统默认展示最近 3 天内的数据。
您也可以在右上角的时间选择器中单击 3d 下拉框,选择 近 1 小时、近 6 小时、近 1 天、近 3 天 或 自定义时间。
将光标悬停在问号图标
 上方,可以查看监控指标说明。
上方,可以查看监控指标说明。
单击租户名称后的图标
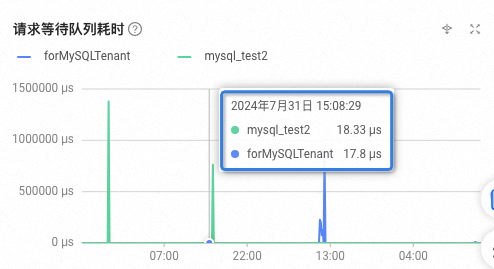
 ,可以查看该租户的监控数据。例如,下图显示了 forMySQLTenant 租户的请求等待队列耗时 数据。
,可以查看该租户的监控数据。例如,下图显示了 forMySQLTenant 租户的请求等待队列耗时 数据。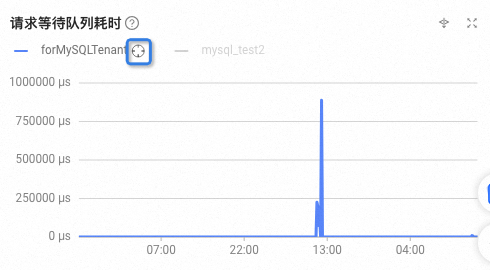
单击下钻图标
 ,可以查看监控指标的细分数据。
,可以查看监控指标的细分数据。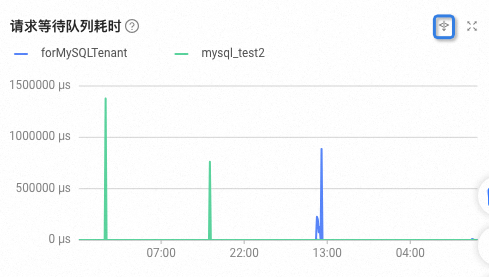
将光标置于某个时间点处,可以查看该时间点的监控数据。
查看异常事件
登录 OceanBase 管理控制台。
在左侧导航栏,选择 自治服务 > 诊断中心。
在 实例详情 区域,单击目标实例名称。
系统自动跳转到诊断中心。
在左侧导航栏,单击 异常应急。
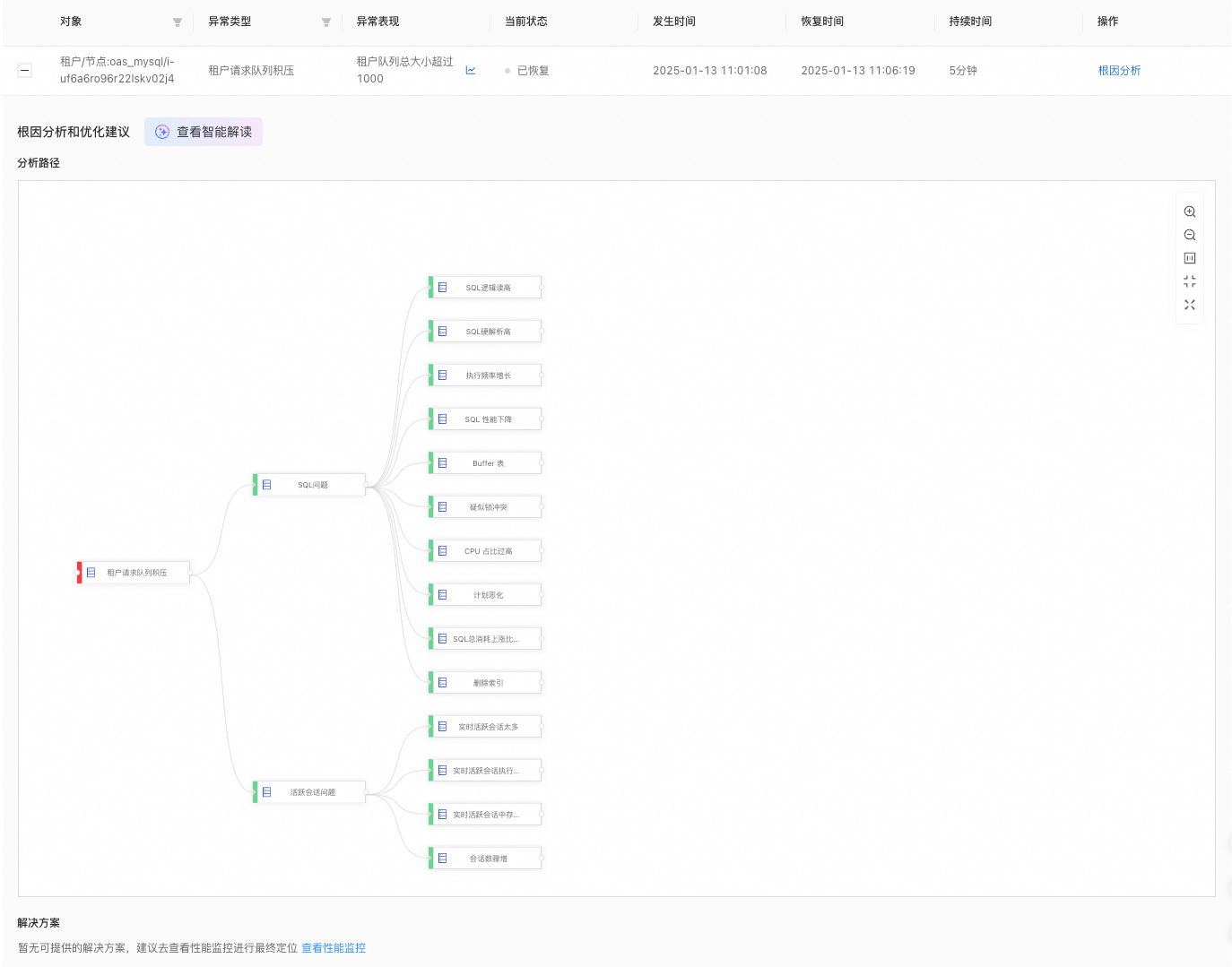
在 异常事件 区域,查看目标对象的异常事件,包括 对象、异常类型、异常表现、当前状态、发生时间、恢复时间、持续时间、操作。
单击单个事件 操作 列的 根因分析,查看该事件的根因分析和优化建议。
说明您可以单击 查看智能解读,查看 AI 提供的诊断结果和诊断建议。AI 智能解读内容,仅供参考。
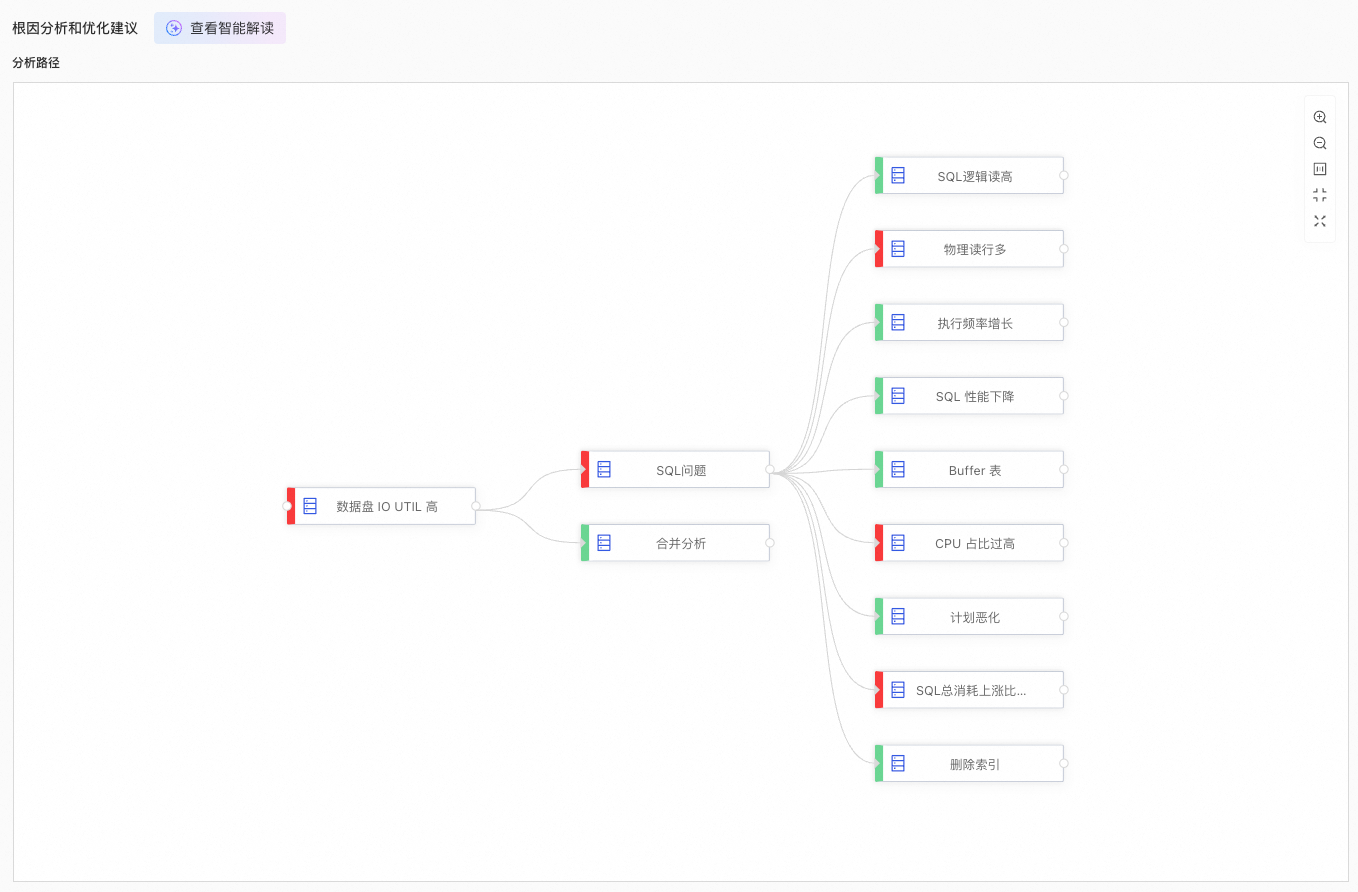
如果异常事件的原因在分析图谱中,系统会红色高亮显示该原因,并提供优化建议。
说明在分析图谱中,每个节点代表一条分析规则。当进行异常分析时,系统会遍历图谱以找到根因节点。根因节点会被红色高亮显示,而绿色节点则表示该规则未命中根因。
示例如下:
当指定时间段内 数据盘 IO UTIL 高 时,系统提供 物理读行多、CPU 占比过高 和 SQL 总消耗上涨比例超过阈值 的提示。在分析路径 区域,您可以单击红色高亮方框查看对应的根因分析。
在 SQL 汇总信息 区域,系统默认显示 SQL 汇总时间段、总执行次数、总报错次数、最大响应时间(ms)、CPU 时间(ms)、计划生成时间(ms)。您可以通过单击 列管理 查看更多信息。

在 可能的根因 SQL 区域,您可以查看可能引起该问题的 SQL,并单击 操作 列的 查看 SQL 详情。

如果异常事件的原因不在分析图谱中,系统会在 解决方案 区域提供建议。示例如下:
当发现 租户请求队列积压 时,系统仍会显示分析图谱,并在 解决方案 区域提供建议。
开启系统自治
OAS 目前提供两个后台任务:
异常事件分析:当系统检测到异常事件时,自动分析与该事件相关的 SQL。
SQL 日常巡检:定期巡检集群中的 SQL,发现可疑 SQL。
当系统分析出与异常事件相关的 SQL,或在日常巡检过程中发现 SQL 执行计划恶化时,OAS 可以自动执行以下操作:
自动刷新 PlanCache:清除 SQL 的执行计划缓存,使优化器重新生成执行计划。
自动绑定 Outline:基于 SQL 历史执行计划的性能统计值,为执行计划恶化的 SQL 自动绑定历史上 CPU 时间较低的执行计划。
操作步骤
登录 OceanBase 管理控制台。
在左侧导航栏中,选择 自治服务 > 诊断中心。
在 实例详情 区域,单击目标实例名称,系统将自动跳转到诊断中心页面。
在左侧导航栏中,单击 异常应急。
在页面右上角,单击 自治设置。
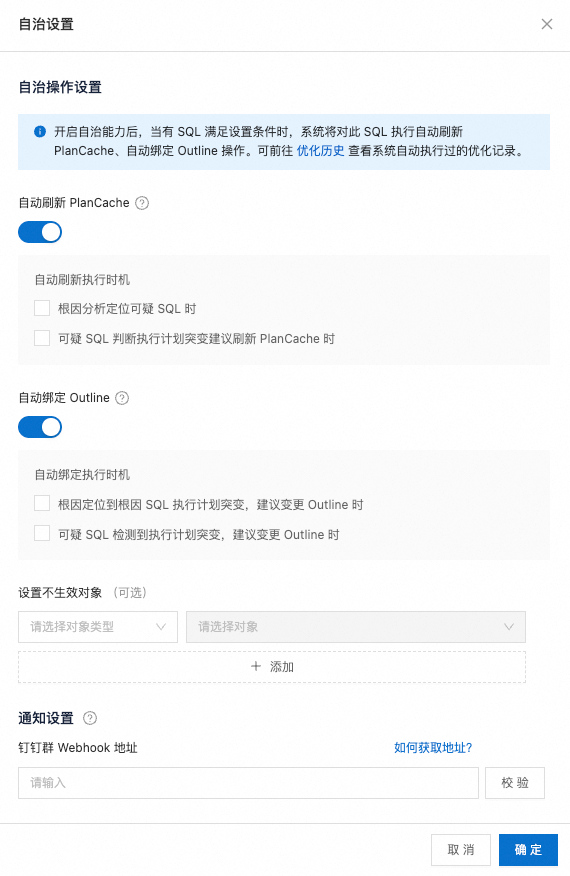
在弹出的窗口中,打开特性开关,并进行以下设置:
自动刷新 PlanCache:设置开启状态和执行时机。
自动绑定 Outline:设置开启状态和执行时机。
设置不生效对象(可选):设置数据库、租户或 SQL 黑名单,系统自愈时将自动忽略这些对象。
通知设置:配置钉钉群通知的 Webhook 地址,具体如下:
在钉钉群中创建机器人,并复制 Webhook 地址链接。获取方式参见 获取自定义机器人 Webhook 地址。
将链接输入文本框,单击 校验,OAS 会向该钉钉群发送验证码。
输入验证码,完成校验。
 说明
说明开启系统自治特性后,可在自治服务 > 诊断中心 > 优化管理 > 优化记录 中查询自动刷新和自动绑定执行计划的记录,相关记录的操作来源为:系统自治。
目前自愈功能仅支持
SELECT类型的 SQL。
自动刷新 PlanCache
SQL 巡检时:仅对存在执行计划恶化的 SQL 自动刷新 PlanCache。
根因分析时:对所有与异常事件关联的 SQL 自动刷新 PlanCache。
自动绑定 Outline
绑定前检查:
系统会尝试刷新 SQL 的执行计划,并观测新生成的执行计划。
如果新执行计划的 CPU 时间比历史执行计划低 20%,则视为自愈成功,不再绑定 Outline。
如果没有生成更好的执行计划,则执行绑定操作,并在上述钉钉群发出告警通知。
绑定后观测:
绑定完成后,系统会继续观测该 SQL 的执行计划。
如果绑定后没有生成更好的执行计划,则回滚绑定操作,并在上述钉钉群发出告警通知。
注意事项:
自动绑定 Outline 基于历史执行计划的性能统计值,为执行计划恶化的 SQL 绑定历史上 CPU 时间较低的执行计划。
在 大小账号场景 中,绑定操作不一定能保证 SQL 性能提升,请密切关注自愈告警通知,及时确认绑定效果。
对于已开启内核 SPM(SQL Plan Management) 的集群,建议不要启用自动绑定 Outline,以免与 SPM 功能冲突。