LucaOne操作手册
本文介绍了阿里云联合科研单位共同发表的研究成果:LucaOne的使用。
如何通过白屏化操作使用LucaOne服务
打开进入页面:
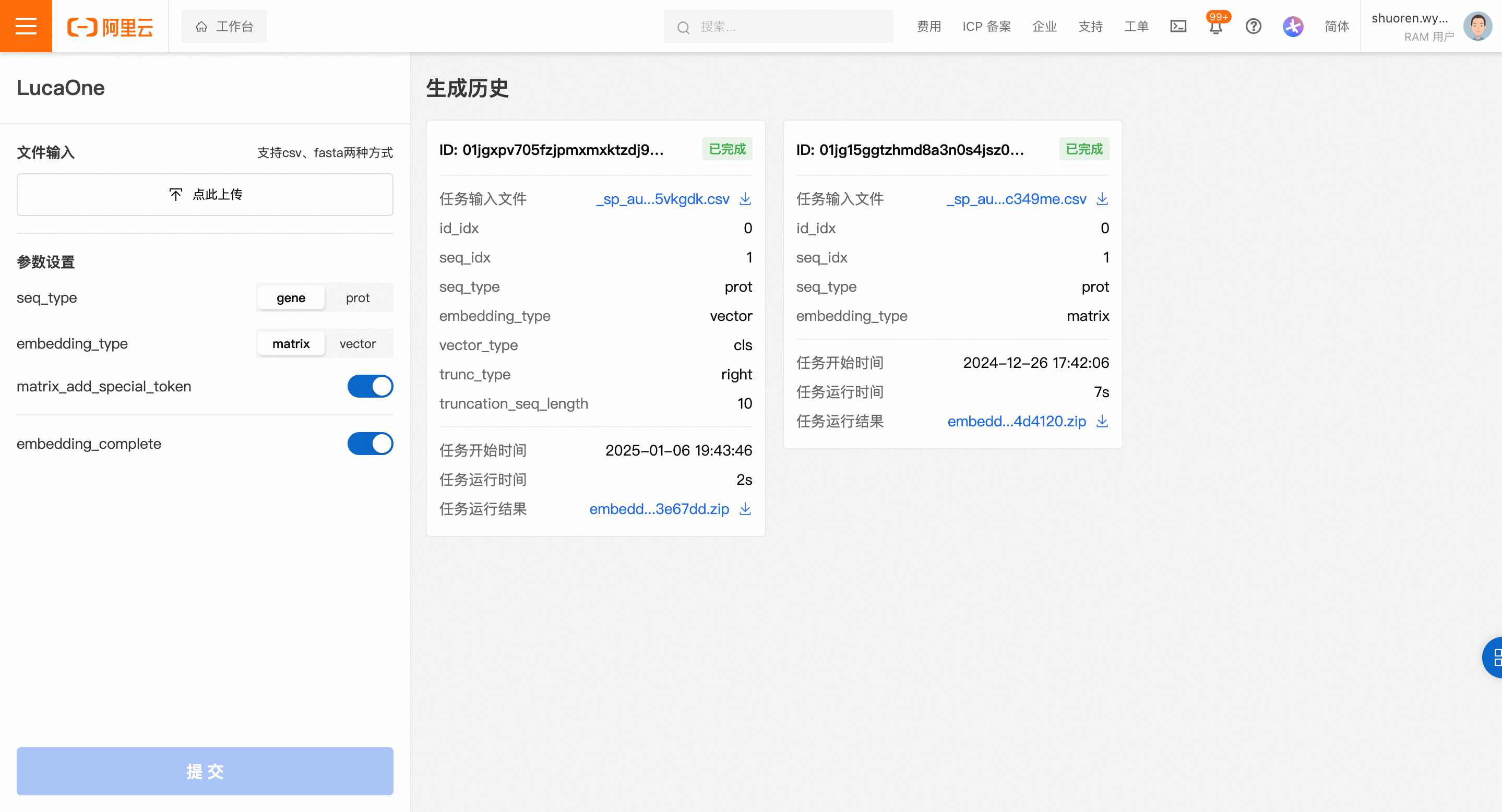
操作步骤
第一步,上传文件
点击上传文件按钮,选择本地文件。
文件格式支持csv、fasta两种。
若是使用csv格式,还需要注明编号的index(id_idx)以及序列的index(seq_idx)
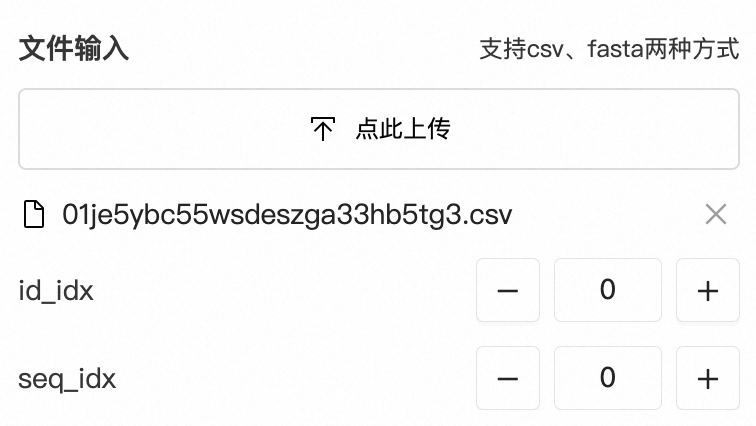
若是使用fasta格式,则无需指定,直接进行下一步。
目前单次任务仅支持最多500条序列。如果超过500条,系统将会报错,请分批处理。
第二步,配置参数
参数说明如下:
参数名称 | 选项说明 | 备注 |
seq_type | 指定序列类型:
| |
embedding_type | 序列embedding的方式:矩阵(seq_len * 2560 或者(seq_len + 2) * 2560) 或者 向量(2560维):
| 建议: 1)如果用于对序列集进行聚类等分析,建议embedding成vector,优先选择mean与max。 2)如果基于embedding进行下游AI模型构建,比如常规的分类或者回归任务,建议使用matrix,然后使用matrix作为下游任务模型的输入去构建,模型中使用参数化的pooling方式。 |
vector_type | vector类型选择:
| |
matrix_add_special_token | Embedding矩阵是否带特殊字符向量。 若是该选项打开,embedding矩阵首尾包含特殊字符向量,矩阵行数为:序列长度+2,对应序列为:[CLS]ATCGATCG[EOS]; 若是该选项不打开,embedding矩阵则不包含特殊字符向量。 | |
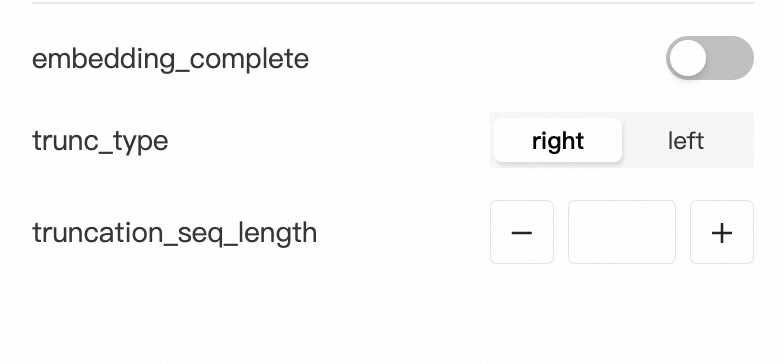
embedding_complete | 若是该选项打开,则会计算整个序列,即参与embedding的是整个序列。 若是该选项关闭,则需要选择序列截断类型以及截断长度:
trunc_type 截断方向:
truncation_seq_length:序列截断长度设置,需要为正整数 |
第三步,提交任务
点击提交任务后,即会运行该任务。一次仅可以提交一个任务。若是有批量跑任务的需求,可以通过API调用来完成。
第四步,结果查看下载
提交任务后,生成历史会有相关任务的记录。
若是在运行中,则会展示运行进度:
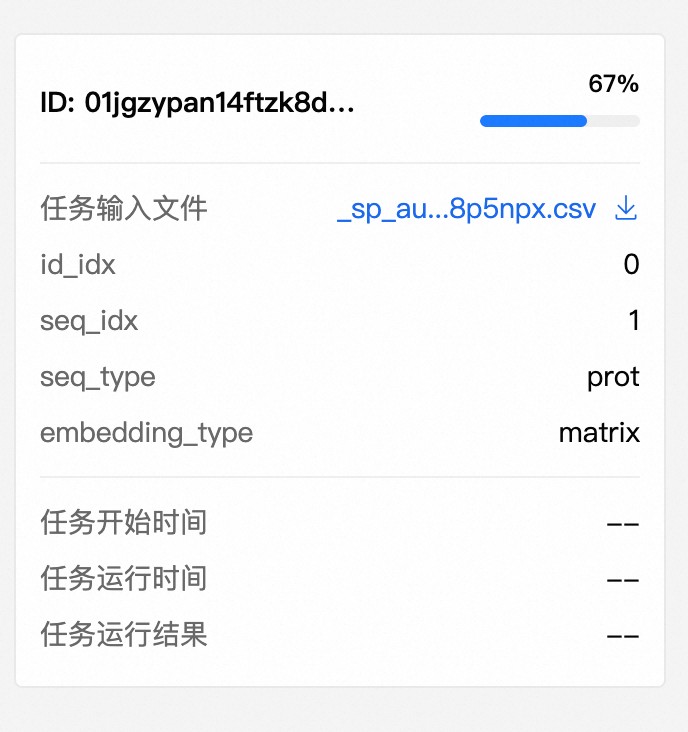
此时,可以关闭该页面或者切换至其他页面进行操作。但是无法继续同步提交其他任务。
若是运行结束,则会展示为已完成状态。
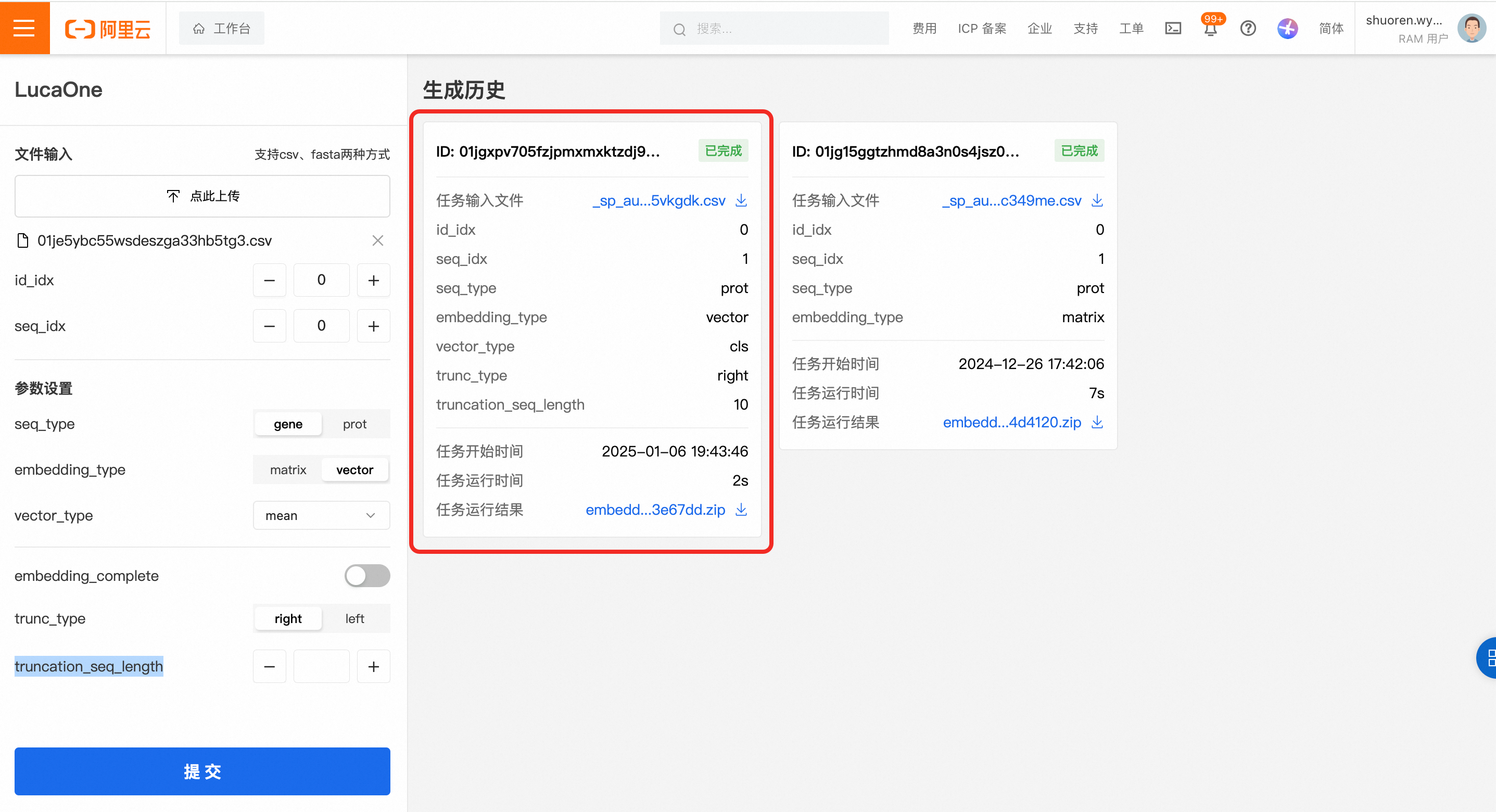
完成后,可以在任务卡片最下方的任务运行结果处下载模型输出结果。
若是任务失败,可以查看报错原因。
若是由于出入参数的问题导致任务失败,请重新配置参数后提交。
若是由于其他原因,如网络原因等,可以一键重新提交。
如何通过API调用LucaOne?
前提条件
提交任务
提交任务接口参考:提交工作流任务 - comfy_prompt
请求体格式:
名称 | 类型 | 必填 | 描述 | |
workflow_id | string | 固定值: 01jfyvw0vmvhewzdxk9jqgznb5 | 工作流ID,固定值,可以在工作流管理里拷贝 | |
alias_id | string | 固定值: main | 工作流别名,别名可以理解为指向特定版本的指针。您可以利用别名来轻松实现发布、回滚等操作 | |
inputs | object | 必填 | inputs 的格式跟具体工作流有关,为您在工作流发版时配置的字段映射。以下内容是一个示例 | |
input_file | string | 必填 | 蛋白质或基因序列,支持 csv、fasta 两种格式 | |
seq_type | string | 必填 | 序列类型 | |
id_idx | integer | input_file 为 CSV 格式时必填 | 序列ID所在列的索引,索引从 0 开始。 | |
seq_idx | integer | input_file 为 CSV 格式时必填 | 序列所在列的索引,从 0 开始。 | |
embedding_type | string | 序列 embedding 矩阵 pooling 成向量的策略设置:
| 建议: 1)如果用于对序列集进行聚类等分析,建议embedding成vector,优先选择mean与max。 2)如果基于embedding进行下游AI模型构建,比如常规的分类或者回归任务,建议使用matrix,然后使用matrix作为下游任务模型的输入去构建,模型中使用参数化的pooling方式。 | |
vector_type | string | 当 embedding_type 为 vector 时必填 | LLM 向量嵌入类型,支持:mean|max|cls 三种类型 | |
trunc_type | string | 如果序列超过最大长度则截断,right或者left | ||
truncation_seq_length | integer | 最大长度(不包括[CLS]与[SEP]),本身不限制长度,取决于embedding推理的显存 | ||
matrix_add_special_token | integer | 如果embedding是matrix,则matrix是否包括[CLS]与[SEP]向量 | ||
embedding_complete | 当 | |||
请求体示例:
{
"workflow_id": "01jfyvw0vmvhewzdxk9jqgznb5",
"alias_id": "main",
"inputs": {
"input_file": "https://example.com/example.csv",
"seq_type": "prot",
"id_idx": 0,
"seq_idx": 1,
"embedding_type": "vector",
"vector_type": "cls",
"embedding_complete": true
},
"randomise_seeds": true
}轮询进度
轮询进度接口参考:查询节点进度信息 - comfy_get_progress
如果不关注执行进度百分比,此步骤也可跳过,直接使用下一步查询结果接口轮询结果。
查询进度示例:
{
status: 10,
apiInvokeId: 'i_677e377e9b80590025ff8822',
data: {
etaRelative: 0.09264909,
currentImage: '',
progress: 0.6666667,
state: {
maxPasses: 0,
pass: 0,
nodeTitle: 'Sp LucaOne Infer Embedding',
step: 0,
maxSteps: -1,
nodeLabel: 'Sp LucaOne Infer Embedding'
},
message: '正在执行节点 Sp LucaOne Infer Embedding',
taskId: '01jh2gha21panx38qb5gfxd085',
status: 'running'
}查询结果
查询结果接口参考:查询工作流执行结果 - comfy_get_result
输出字段格式:
名称 | 类型 | 描述 | |||
status | integer | 网关状态码,10: 成功,20: 失败 | |||
apiInvokeId | string | 系统生成的标志本次调用的id。 | |||
errCode | string | 网关错误码,成功忽略。 | |||
errMessage | string | 网关错误详情,成功忽略。 | |||
subErrCode | string | 服务错误码,成功忽略。 | |||
subErrMessage | string | 服务错误详情,成功忽略。 | |||
data | object | 服务返回结果 | |||
status | string | 任务状态 任务成功:succeeded; 任务执行失败:failed; 任务执行中:running; 排队中:waiting。 | |||
taskId | string | 生图任务ID | |||
taskDuration | long | 执行时长,单位(毫秒) | |||
taskBeginTime | long | 任务开始时间,13 位时间戳 | |||
taskEndTime | long | 任务结束时间,13 位时间戳 | |||
result | object | 自定义输出字段,当接口发布时配置自定义输出后该字段有效。 | |||
embedding | object | 词嵌入文件,zip 格式 | |||
url | string | 可公共访问的文件地址 重要 文件具有有效期,如果需要长期使用,建议转存到私有文件仓储 | |||
查询结果示例:
{
"status": 10,
"apiInvokeId": "i_677e388319c46d002503b84c",
"data": {
"result": {
"embedding": {
"filename": "embedding5f6305a1a7bb4f90bf941b104699add3.zip",
"object_key": "comfy/output/lucana/embedding5f6305a1a7bb4f90bf941b104699add3.zip",
"subfolder": "lucana",
"type": "output",
"url": "https://example.com/example.zip"
}
},
"images": [
"http://example.com/example.zip"
],
"taskDuration": 34642,
"taskBeginTime": 1736325216019,
"taskId": "01jh2grdqs7t24x60dpay3qajv",
"status": "succeeded",
"taskEndTime": 1736325250661
},
"subErrCode": null,
"subErrMessage": null,
"errCode": null,
"errMessage": null,
"startTime": null,
"endTime": null,
"requestId": null
}