在复购预测中,需要先完成模型配置,当且仅当模型执行成功后,可基于模型进行复购预测。
模型训练成功后,您可以查看训练中前10个最重要的特征,并通过模型验证了解该模型的准确率、召回率预期。
前提条件
算法模型需要依赖行为数据集作为训练数据,经算法引擎学习后生成可用的模型。算法模型的优劣依赖于训练数据,数据质量越高,数据量越大,算法效果越好。
创建算法模型
由于一个工作空间只能运行一个模型。若当前空间已有状态为“训练成功”的模型,您需要先将其下线,才能创建新的模型。
列表上方提示已用模型任务数/购买的可用模型任务数,为组织下所有空间的总和。新建和更新模型均消耗可用模型任务数,执行失败的不计数。
操作步骤:
选择工作空间>用户洞察>复购预测>模型配置。
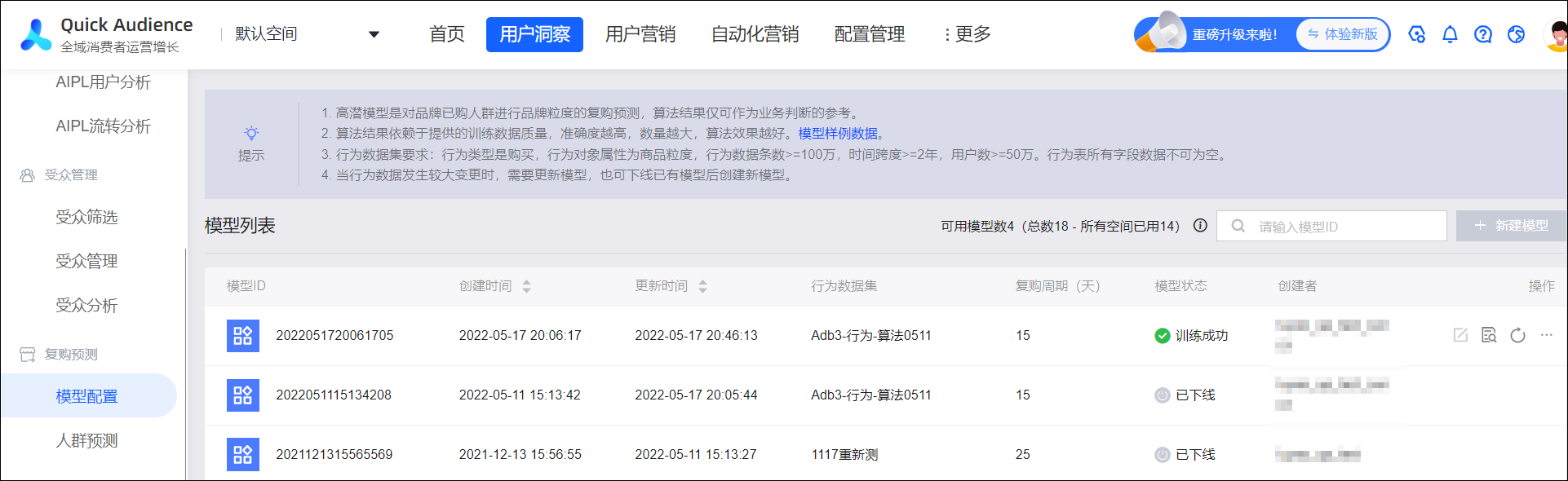
单击右上角新建模型,配置页面如下图所示。
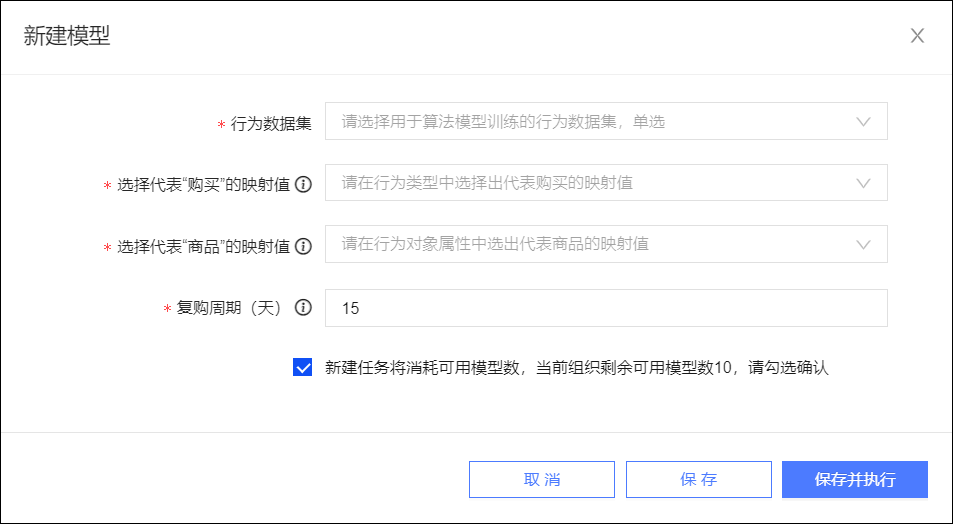
选择行为数据集作为训练数据。
选择“购买”在行为数据集的行为类型字段中的映射值。
选择“商品”在行为数据集的行为对象属性字段中的映射值。
输入复购周期(天),支持15~90的整数,即设置为预测未来N天内的用户复购。
说明“未来N天”是指以行为数据集的最近行为时间为基准,从该天起的未来N天。
勾选确认新建任务将消耗可用模型任务数,单击保存并执行,系统将开始训练模型。
若单击保存,则仅保存配置。
管理算法模型
算法模型列表如下图所示。

其中,模型状态分为:
未开始:仅保存未开始训练的模型。
待训练:当组织中正在执行的模型训练和人群预测任务数超过5个时,超出的模型将排队等待训练。
训练中
训练成功:模型训练成功后,本空间的人群预测任务将默认使用该模型。
训练失败:模型训练达到24小时无结果时,自动停止训练,以及发生手动结束训练等情况时,为训练失败。鼠标移动到
 图标上将显示失败原因。
图标上将显示失败原因。已下线
您可以对模型进行编辑、查看训练详情、手动更新、结束训练、下线等操作。
编辑
对于未开始、训练失败的模型,您可以单击 图标,修改模型配置,配置方法与创建时相同。
图标,修改模型配置,配置方法与创建时相同。
查看训练详情
对于训练成功的模型,您可以单击 图标,查看训练的详细信息,请参见下面的查看训练详情。
图标,查看训练的详细信息,请参见下面的查看训练详情。
手动更新
对于非待训练、训练中的模型,您可以单击 图标,重新训练该模型,生成一个新模型代替原模型。
图标,重新训练该模型,生成一个新模型代替原模型。
为了预测的准确性,建议当训练数据量发生较大变化时更新模型。当系统检测到行为数据集的数据量增幅达到20%时,将在行为数据集名称后显示图标,提示您对模型进行更新。
开始重新训练模型前,将出现弹窗,提示若模型训练成功,将消耗可用模型任务数,并且开始训练后原模型将下线,单击确认后才能开始训练。
下线
对于非待训练、训练中的模型,您可以单击 >下线,将该模型下线。
>下线,将该模型下线。
下线后的模型,若无关联的预测任务,将直接删除模型数据。
查看训练详情
对于训练成功的模型,单击训练详情,进入详情页面,查看模型信息、训练特征Top10和模型验证,如下图所示。
训练特征Top10
了解训练特征Top10有助于您理解人群预测的结果人群中较显著的行为特征。
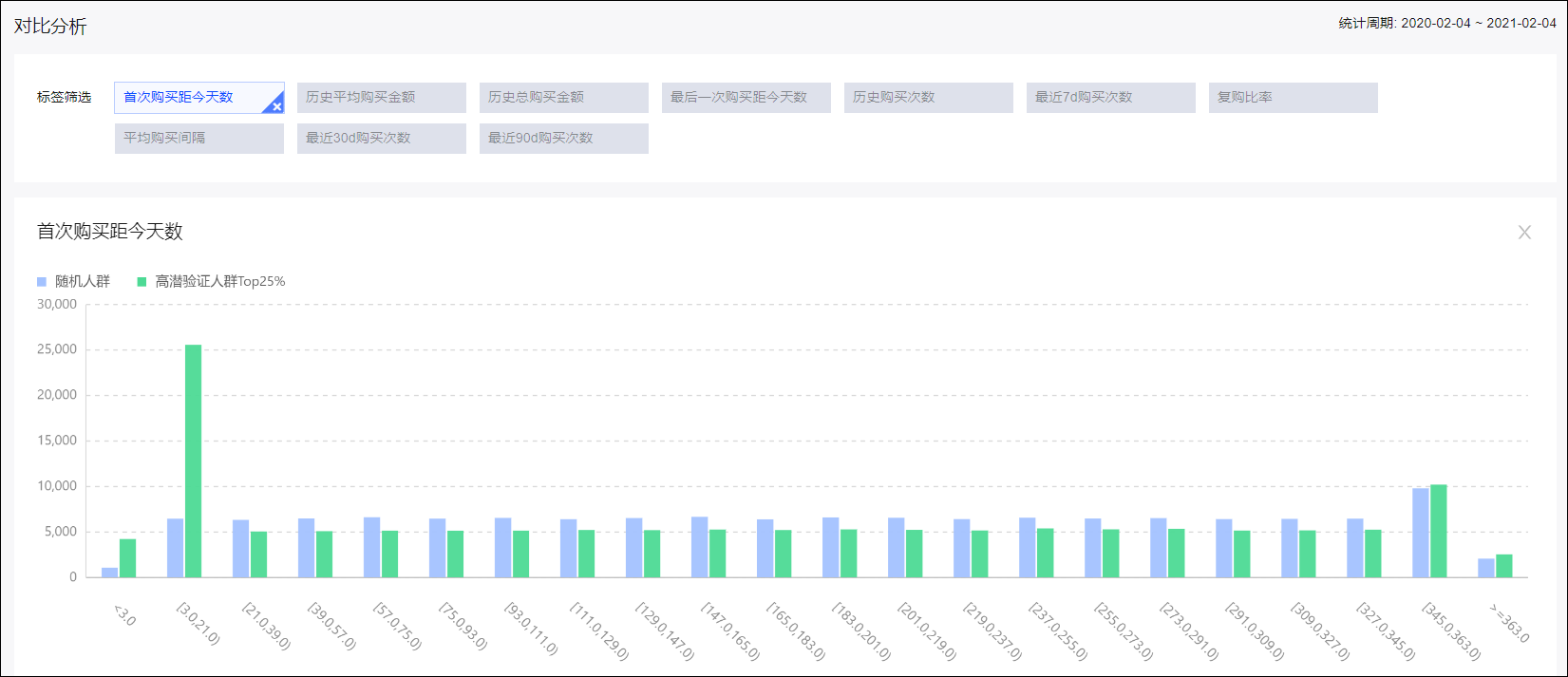
训练特征Top10是训练中前10个最显著的训练标签特征,即算法模型中重要性比较高的10个用户指标。如需要了解预测结果人群与随机人群的训练特征Top10对比情况,请查看模型验证。
训练特征Top10如下图所示。
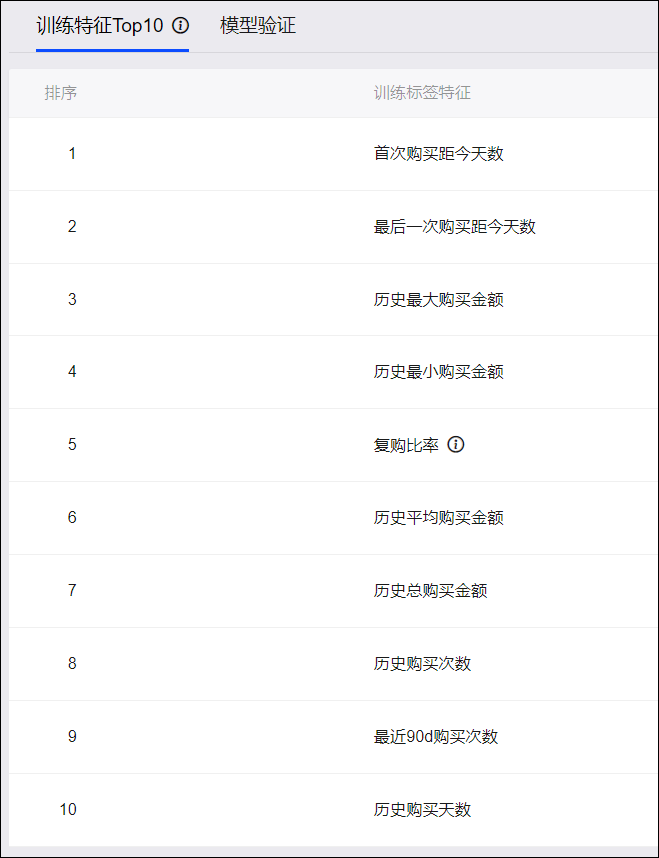
所有训练标签特征均为训练算法模型时由原始行为数据加工获得,其含义如下表所示。
训练标签特征 | 含义 |
历史平均购买金额 | 用户的购买总金额/用户购买次数 |
历史最大购买金额 | 用户的最大购买金额 |
历史最小购买金额 | 用户的最小购买金额 |
历史总购买金额 | 用户的购买总金额 |
历史购买次数 | 用户的购买次数 |
最近7d购买次数 | 近7天用户购买次数 |
最近30d购买次数 | 近30天用户购买次数 |
最近90d购买次数 | 近90天用户购买次数 |
首次购买距今天数 | 用户首次购买距今天数 |
最后一次购买距今天数 | 用户最后一次购买距今天数 |
历史购买天数 | 计算用户发生过购买的天数,一天买多次计为1次 |
行为的渠道数 | 购买行为的渠道数 |
平均购买间隔 | 用户购买间隔=最后一次购买和第一次购买的时间间隔/(购买次数-1) |
复购比率 | 用户平均购买间隔/最后一次购买距今天数 |
模型验证
了解模型验证情况有助于您通过准确率、召回率了解预测的效果预期,帮助您在后续的人群预测任务结果中选择恰当人数作为预测用户,以便获得较高的预测效果。
模型验证是取等量人数的随机人群、高潜验证人群,将他们的准确率、召回率做对比,以及将他们的训练特征Top10的取值分布做对比:
首先,系统取等量人数的随机人群、高潜验证人群:
高潜验证人群:从历史人群中抽取部分人群使用模型进行复购预测,将预测出的购买概率最高的前N%人群作为高潜验证人群,人数为M人。
其中,我们将N%分多次取值5%、25%、50%等,总人数M也随之不同,对应在人群预测任务结果中选择不同人数作为预测用户的情况。
随机人群:从历史人群中随机抽取的M人,与高潜验证人群数量相等,作为对照组。
然后,系统分别根据高潜验证人群、随机人群在复购周期内的购买情况计算准确率、召回率,作为预测是否成功的量化指标:
准确率:预测用户(即高潜验证人群或随机人群)中的购买人数/预测用户人数
召回率:预测用户(即高潜验证人群或随机人群)中的购买人数/整个历史人群中的购买人数
随机人群、高潜验证人群的准确率、召回率对比如下图所示。
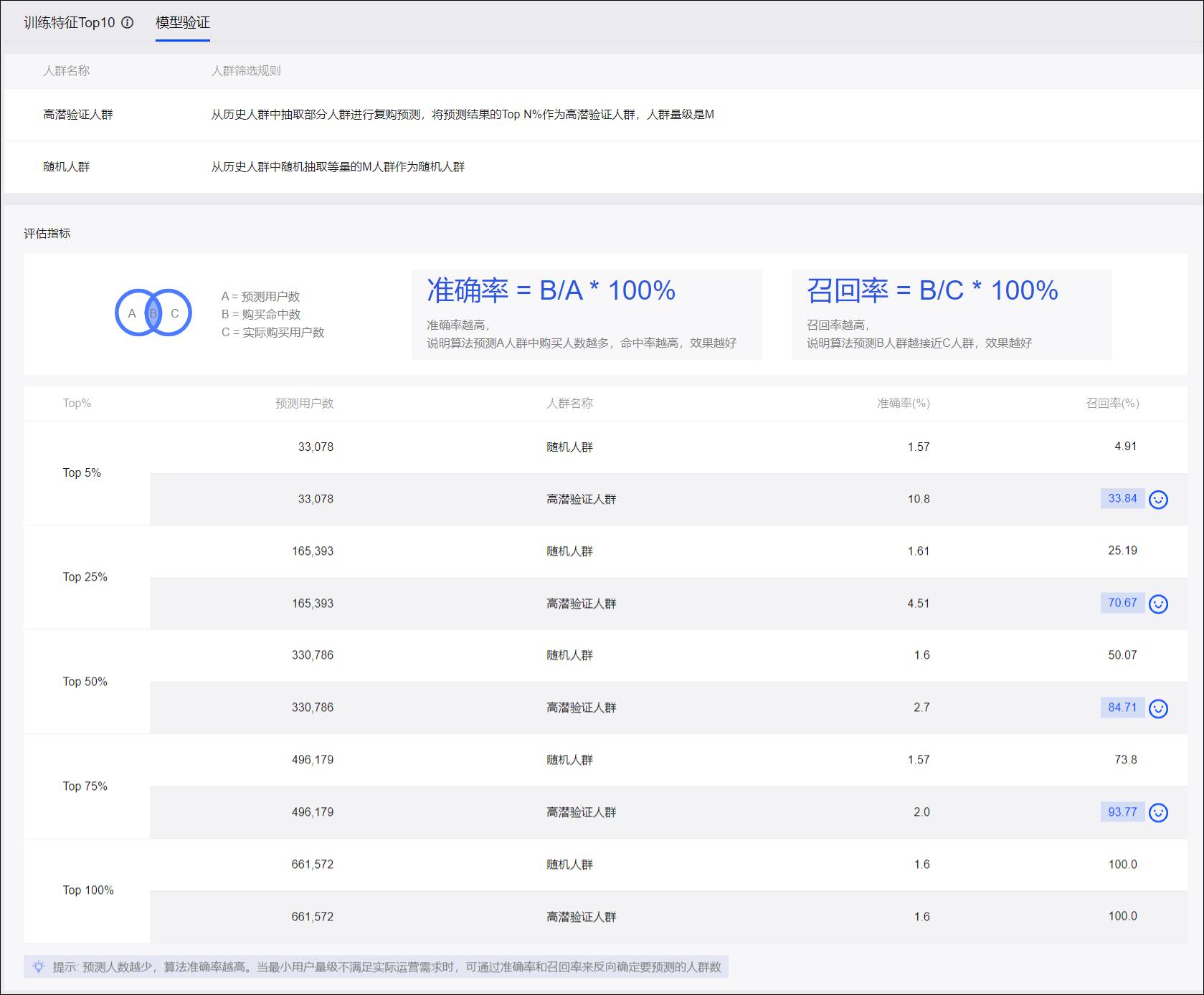
在结果中:
高潜验证人群的准确率、召回率一般比同等人数的随机人群高,说明算法模型成功预测了高潜人群。
人数少的高潜验证人群的准确率、召回率一般比人数多的高潜验证人群高,这是由于历史人群中一般只有部分人的训练特征较为突出,其余人的训练特征数据差距较小。
随机人群的准确率、召回率一般不随人数有大的波动,这是选择随机人群造成的。
因此,在后续的人群预测任务结果中,为了获得较高的准确率、召回率,建议您从中尽量选择人数较少的高购买概率用户作为预测用户,当需要选择更多人数的预测用户时,建议您参考模型验证结果中的准确率、召回率确定人数,具体方法将在人群预测明细结果中说明。
最后,系统将随机人群、高潜验证人群的训练特征Top10的取值分布做对比。
如下图所示,选择标签(即训练特征)后,下方将展示对比图表。数据统计周期为近一年,默认展示的高潜验证人群取购买概率最高的前Top25%。