在货品推荐中,需要先完成模型配置,当且仅当模型执行成功后,可基于模型进行货品推荐。
模型训练成功后,您可以通过模型验证了解该模型的准确率、召回率,并查看商品之间的关联关系。
前提条件
算法模型需要依赖行为数据集、商品标签数据集作为训练数据,经算法引擎学习后生成可用的模型。算法模型的优劣依赖于训练数据,数据质量越高,数据量越大,算法效果越好。
创建算法模型
由于一个工作空间只能运行一个模型。若当前空间已有状态为“训练成功”的模型,您需要先将其下线,才能创建新的模型。
列表上方提示已用模型任务数/购买的可用模型任务数,为组织下所有空间的总和。新建和更新模型均消耗可用模型任务数,执行失败的不计数。
操作步骤:
选择工作空间>用户洞察>货品推荐>模型配置。
单击右上角新建模型,配置页面如下图所示。
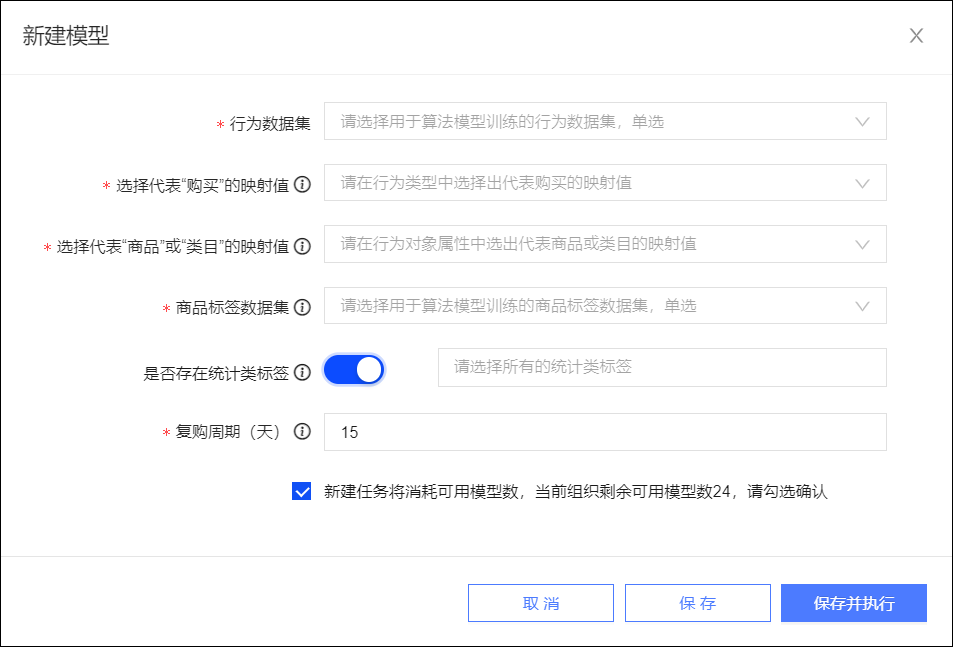
选择行为数据集作为训练数据。
选择“购买”在行为数据集的行为类型字段中的映射值。
选择“商品”或“类目”在行为数据集的行为对象属性字段中的映射值。
说明将类目做为行为数据集的行为对象,可以实现在模型的训练详情页面商品关联预测页签查看类目之间的关联关系。对应地,商品标签数据集的主键必须是类目ID。
选择商品标签数据集作为训练数据。
选择商品标签数据集中是否存在统计类标签,若存在,请选择出全部的统计类标签。
说明统计类标签,例如最近90天销量,将会影响模型训练效果,因此需要全部指出,以便系统在模型训练时排除统计类标签。
输入复购周期(天),支持15~90的整数,即设置为推荐未来N天内的匹配商品。
说明“未来N天”是指以行为数据集的最近行为时间为基准,从该天起的未来N天。
勾选确认新建任务将消耗可用模型任务数,单击保存并执行,系统将开始训练模型。
若单击保存,则仅保存配置。
管理算法模型
算法模型列表如下图所示。
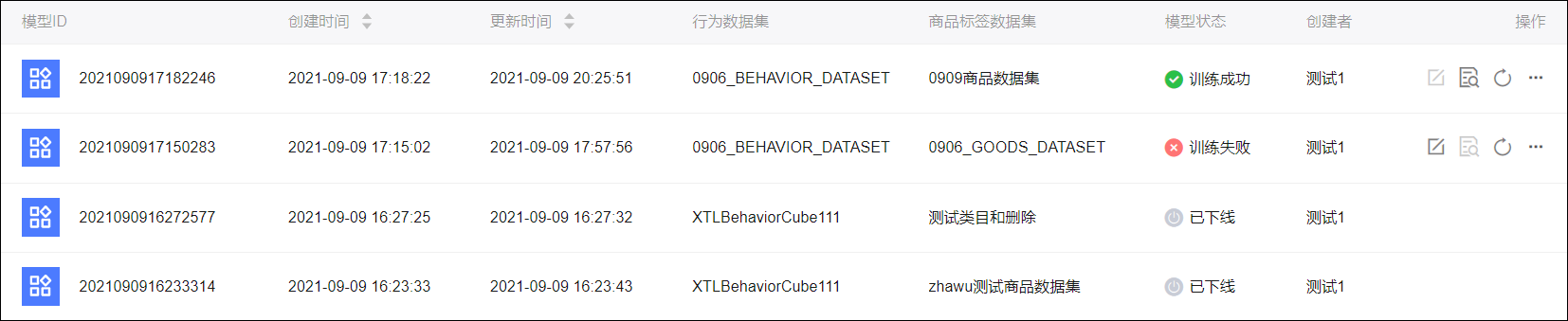
其中,模型状态分为:
未开始:仅保存未开始训练的模型。
待训练:当组织中正在执行的模型训练和商品推荐任务数超过5个时,超出的模型将排队等待训练。
训练中
训练成功:模型训练成功后,本空间的商品推荐任务将默认使用该模型。
训练失败:模型训练达到24小时无结果时,自动停止训练,以及发生手动结束训练等情况时,为训练失败。鼠标移动到
 图标上将显示失败原因。
图标上将显示失败原因。已下线
您可以对模型进行编辑、查看训练详情、手动更新、结束训练、下线等操作。
编辑模型
对于未开始、训练失败的模型,您可以单击 图标,修改模型配置,配置方法与创建时相同。
图标,修改模型配置,配置方法与创建时相同。
查看训练详情
对于训练成功的模型,您可以单击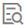 图标,查看训练的详细信息,请参见下面的查看训练详情。
图标,查看训练的详细信息,请参见下面的查看训练详情。
手动更新
对于非待训练、训练中的模型,您可以单击 图标,重新训练该模型,生成一个新模型代替原模型。
图标,重新训练该模型,生成一个新模型代替原模型。
为了推荐的准确性,建议当训练数据量发生较大变化时更新模型。当系统检测到行为数据集的数据量增幅达到20%时,将在行为数据集名称后显示图标,提示您对模型进行更新。
开始重新训练模型前,将出现弹窗,提示若模型训练成功,将消耗可用模型任务数,并且开始训练后原模型将下线,单击确认后才能开始训练。
下线
对于非待训练、训练中的模型,您可以单击 >下线,将该模型下线。
>下线,将该模型下线。
下线后的模型,若无关联的预测任务,将直接删除模型数据。
查看训练详情
对于训练成功的模型,单击训练详情,进入详情页面,查看模型信息、模型验证和商品关联推荐,如下图所示。
模型验证
了解模型验证情况有助于您通过准确率、召回率了解推荐的效果预期,帮助您在后续的商品推荐任务结果中选择恰当的推荐商品数,以便获得较高的推荐效果。
模型验证是取等量人数的随机人群、高潜验证人群,将他们的准确率、召回率做对比:
首先,系统取等量人数的随机人群、高潜验证人群:
高潜验证人群:从历史人群中抽取部分人群使用模型进行商品推荐,人数为M人。然后对每人取推荐结果中的TopN商品。
随机人群:从历史人群中随机抽取的M人,与高潜验证人群数量相等,作为对照组。然后对每人推荐近一年销量TopN的商品。
然后,系统分别根据高潜验证人群、随机人群在预测周期内的购买情况计算准确率、召回率,作为推荐是否成功的量化指标:
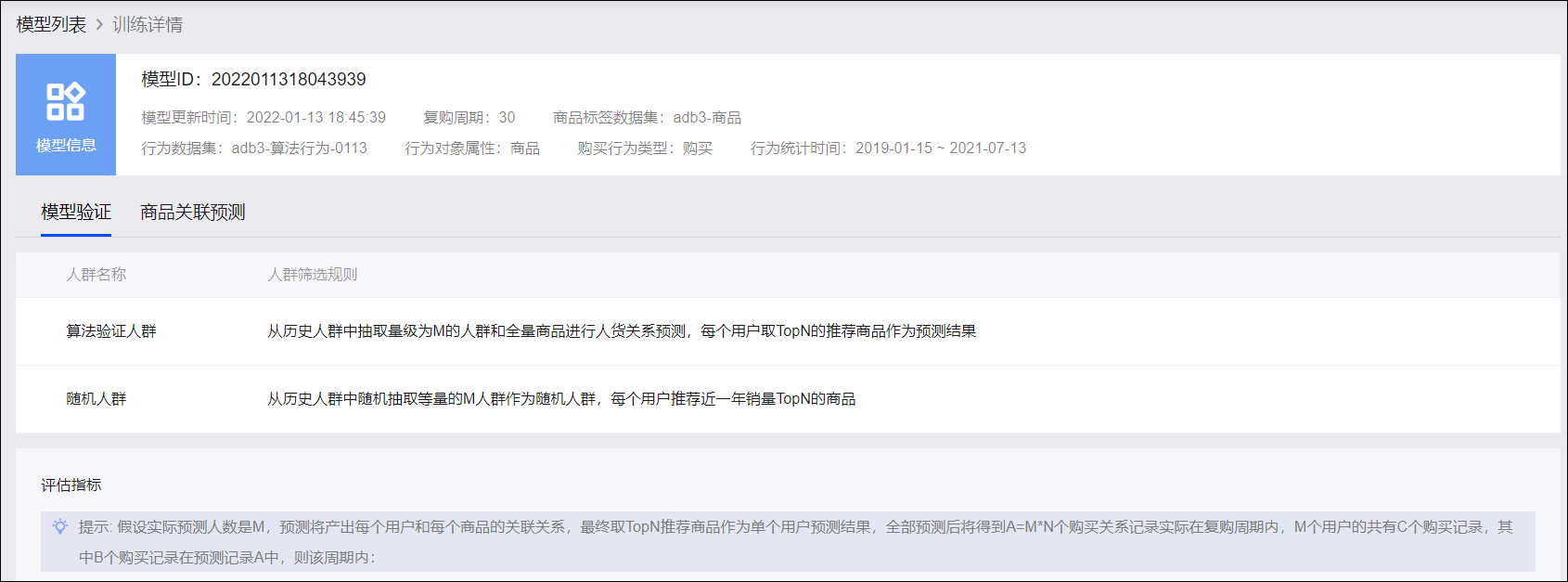
准确率:高潜验证人群或随机人群的命中记录数/预测记录数
召回率:高潜验证人群或随机人群的命中记录数/实际购买记录数
说明预测记录数:一个人的一个推荐商品为一个预测记录,人群中所有人的推荐商品总数M×N为预测记录数。我们将对TopN分多次取值Top3、Top10等,预测记录数也随之不同。
命中记录数:一个人购买一个推荐商品为一个命中记录,人群中所有人购买的推荐商品总数为命中记录数。
实际购买记录数:一个人购买一个任意商品称为一个实际购买记录,人群中所有人购买的任意商品总数为实际购买记录数。
不同的人推荐/购买同一个商品,计为多个记录;同一个人多次购买同一个商品,仅计为1个记录。
随机人群、高潜验证人群的准确率、召回率对比如下图所示。
在结果中:
高潜验证人群的准确率、召回率一般比同等人数的随机人群高,说明算法模型成功推荐了匹配的商品。
TopN的数量少时的准确率一般比TopN的数量多时高,说明推荐商品数量较少时,前几位推荐商品易于产生精准推荐。
TopN的数量多时的召回率一般比TopN的数量少时高,这是由于推荐商品数量增多,命中机会将随之增大。但我们不建议对同一用户推荐过多商品,以免造成用户反感,因此,在创建商品推荐任务时,限制最多推荐10个商品。
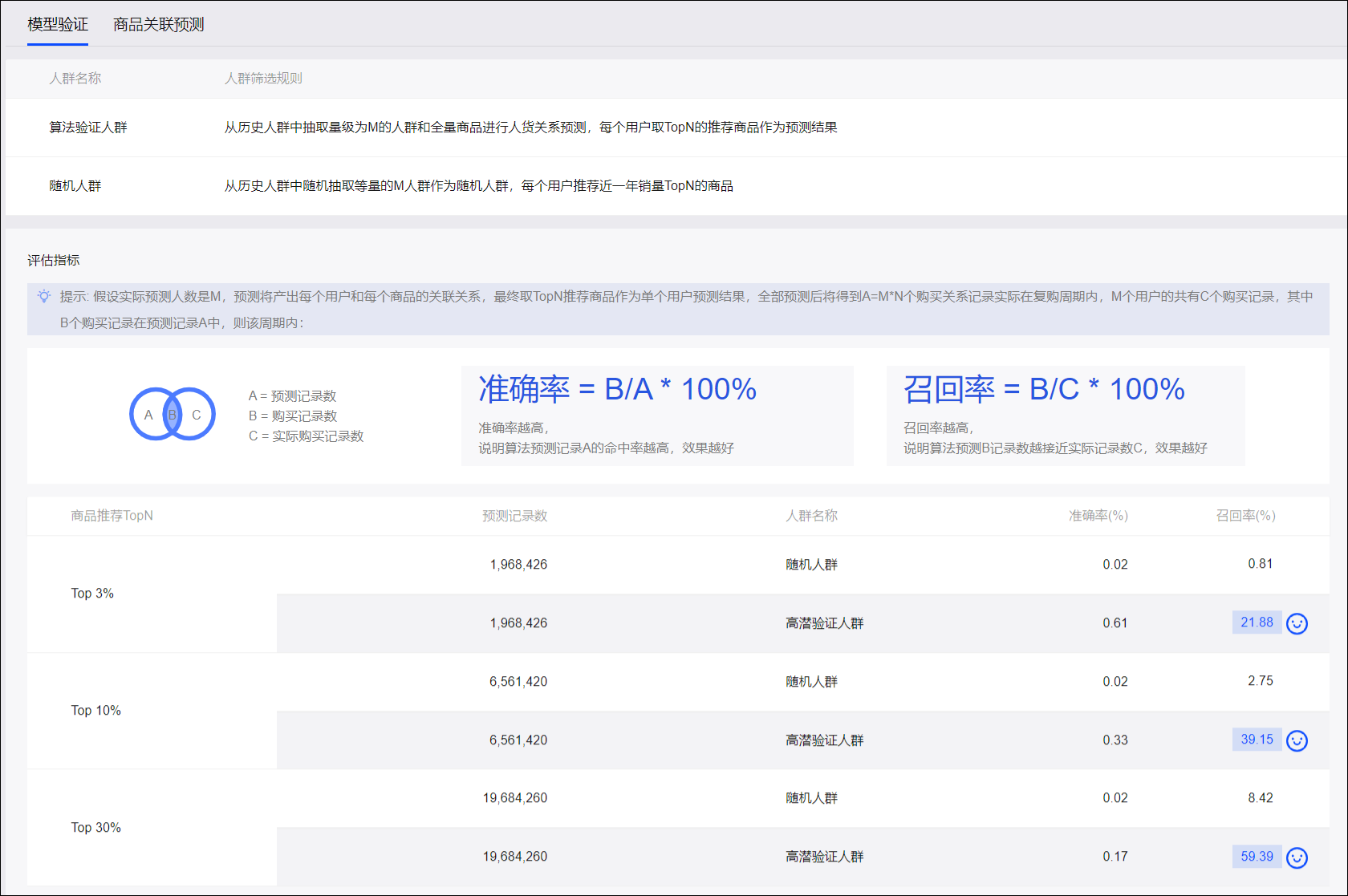
商品关联预测
商品关联预测是指通过分析购买行为和商品的标签特征,计算出商品和商品之间的关联关系。
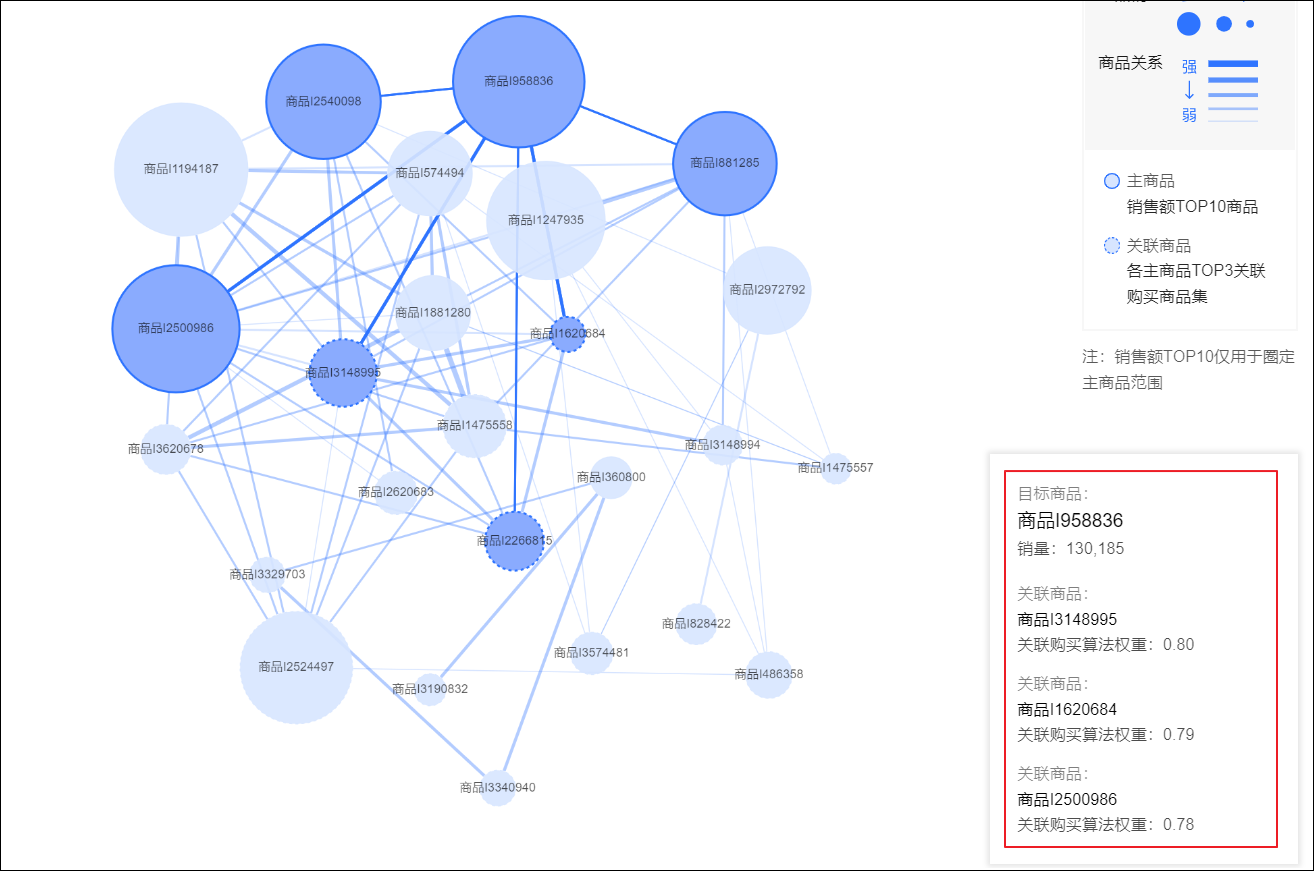
如下图所示,在商品间关联分布视角页签,关联分布图包含销售额Top 10的商品以及与其关联性最强的前3个商品,以关系图的形式展示他们两两之间的关联性。
实线圆圈代表销售额Top 10商品,虚线圆圈代表各销售额Top 10商品的前3个关联最强的商品。
圆圈的大小表示商品的销量,购买次数越多,圆圈越大。
请勿将销售额与销量的表示方式混淆。
线条的深浅粗细表示两个商品间的关联强弱,关系越强线条颜色越深、越粗。
单击图表右上角的
 图标,图表将调整至能展示全部商品的比例。单击
图标,图表将调整至能展示全部商品的比例。单击 放大,单击
放大,单击 缩小,拖拽可移动。
缩小,拖拽可移动。鼠标移动至图表的某个商品后,图中将高亮该商品与其他商品的关联关系,图表右下角将弹窗显示该商品的销量,以及与其关联性最强的前3个商品的关联购买算法权重(取值0~1,数值越大商品关联性越强),如下图所示。
单击图表右上角查看销售额Top10商品数据,可以跳转到销售额 TOP10 商品数据。
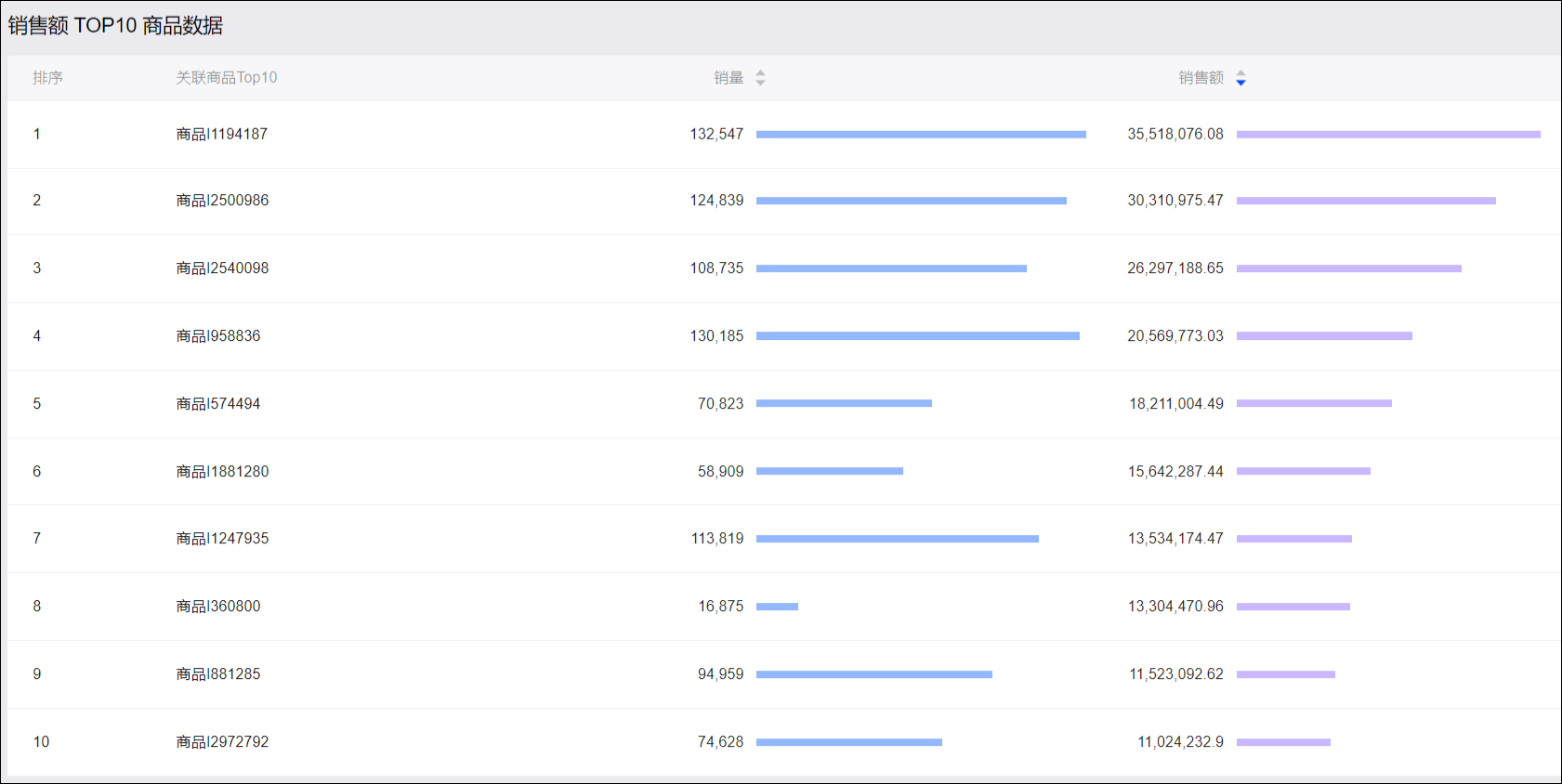
商品间关联分布视角页签下方展示销售额 TOP10商品数据,包括销量、销售额,如下图所示。
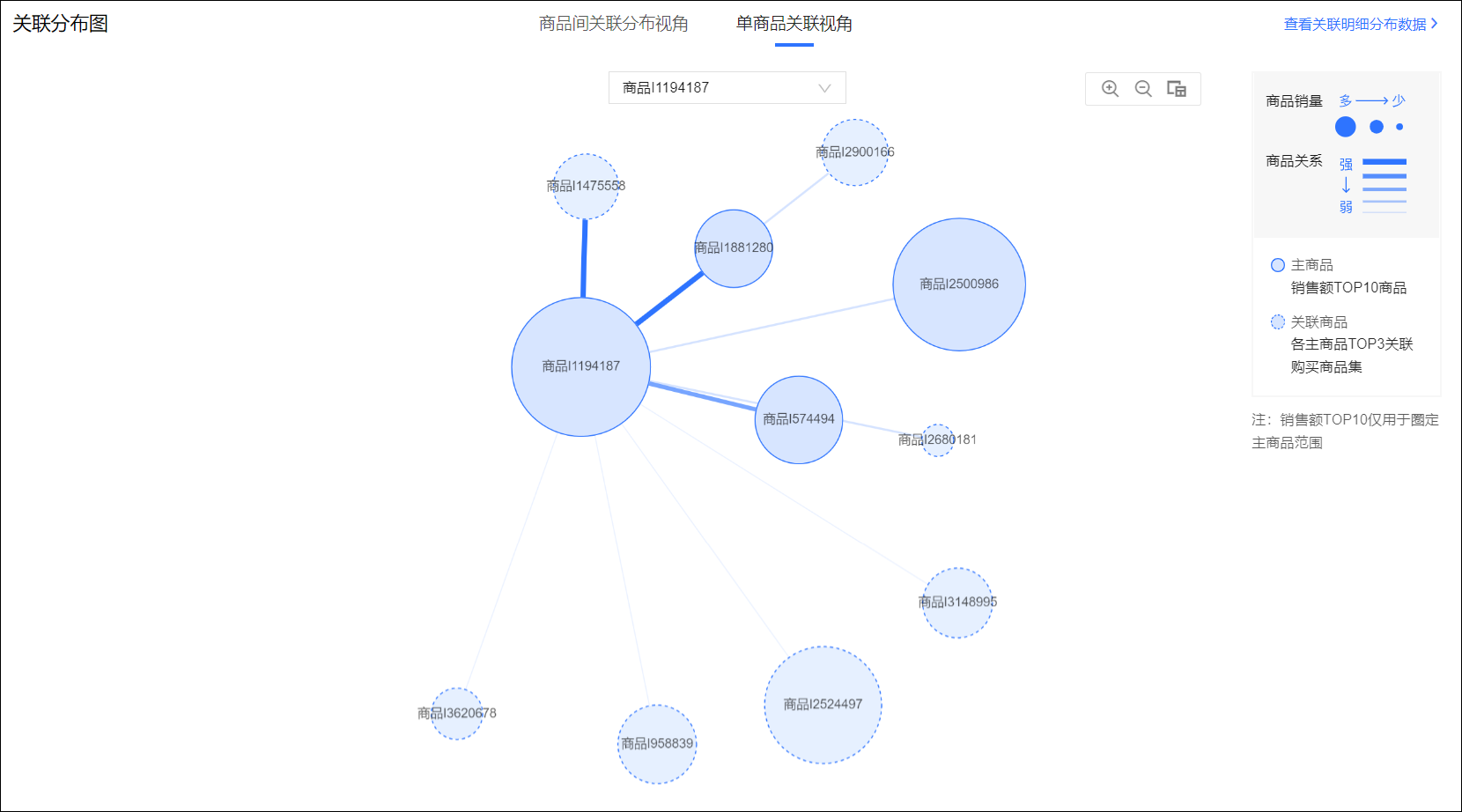
单击选中商品间关联分布视角页签的关联分布图的某个商品后,将进入单商品关联视角页签,展示该商品与其他商品的关联关系。
关联分布图:如下图所示,以该商品为中心,展示该商品与其他商品的关联关系。
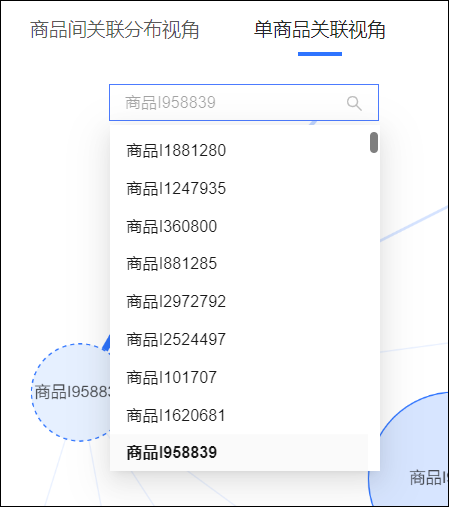
图表上方的下拉框支持切换商品,支持基于商品名称进行搜索。
单击图表右上角查看关联明细分布数据,可以跳转到关联明细分布。
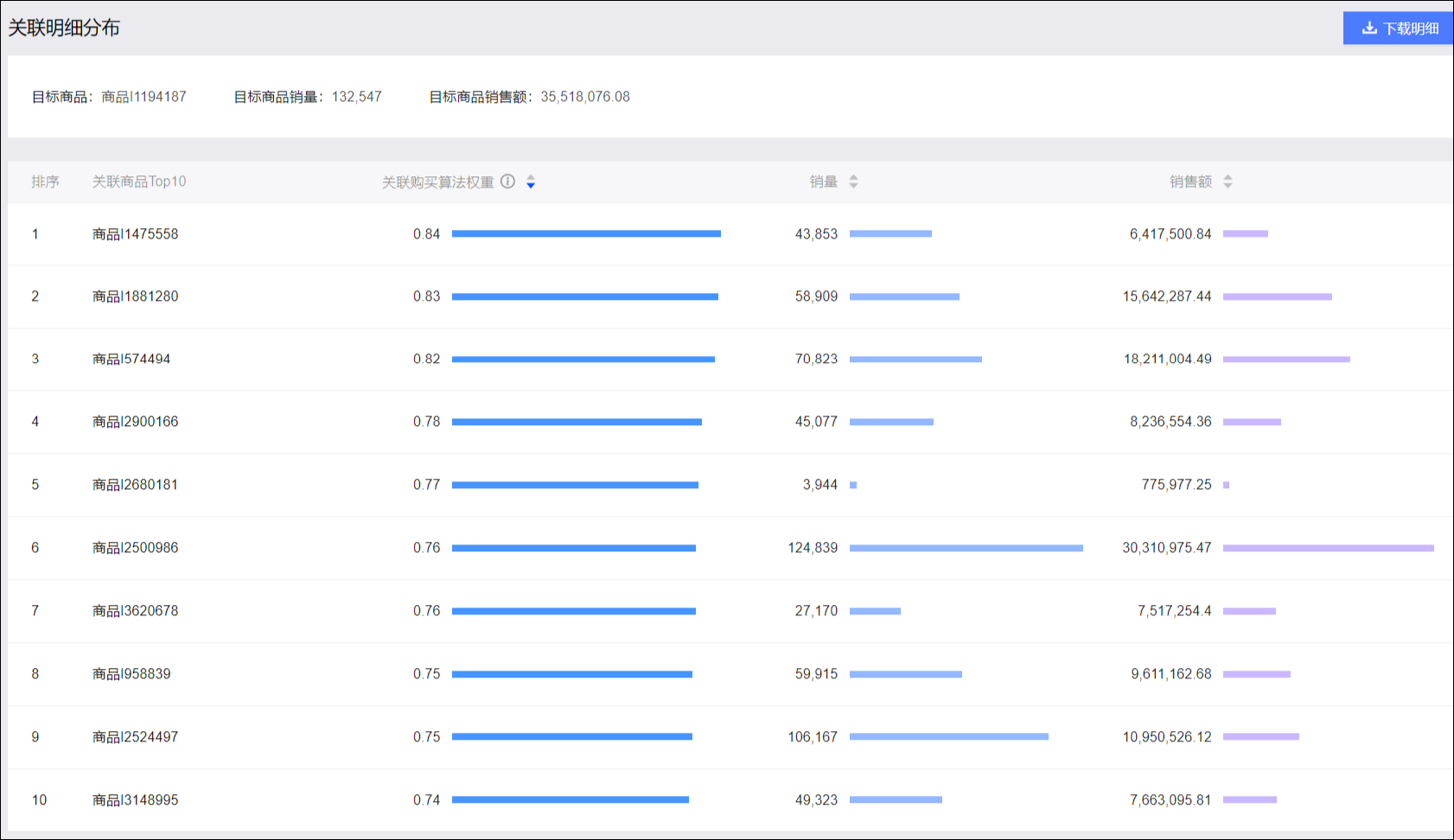
关联明细分布:如下图所示,单商品关联视角页签下方展示该商品的销量、销售额,以及与其关联性最强的前10个商品的关联购买算法权重(取值0~1,数值越大商品关联性越强)、销量、销售额。单击右上角下载明细可下载明细数据。