产品简介
联邦建模是基于联邦学习(Federated Learning,简称 FL)技术,在满足各参与方的合规政策和数据价值保护的需求下,实现模型迭代和更新的服务。
联邦建模服务采用联合计算的模式,实现在原始数据不离开本地的前提下,完成模型的研发和效果评估。
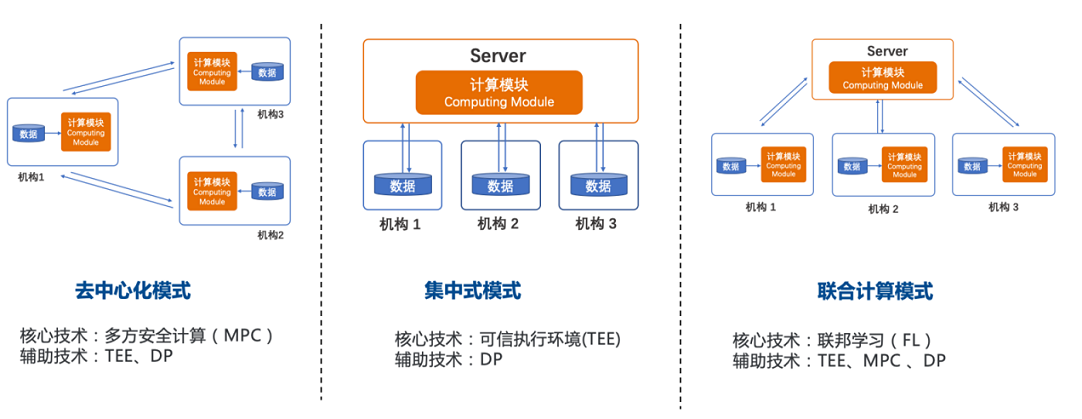
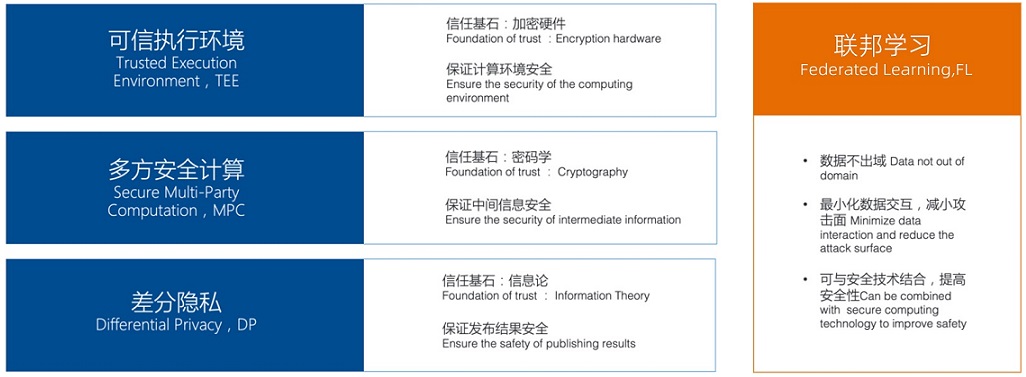
联邦建模产品作为联邦建模服务的可视化操作平台,是面向联邦模型开发者,进行数据处理、模型研发和模型评估的平台。联邦建模集成了联邦学习,可信执行环境(Trusted Execution Environment,简称 TEE)、多方安全计算(Secure Multi-Party Computation,简称 MPC)和差分隐私(Differential Privacy,简称 DP)等技术手段,对差分攻击进行抵御,保护各参与方的中间信息。
产品优势
联邦建模服务具有以下优势:
安全
为了应对联邦建模过程中潜在的数据安全问题,该产品集成了密码学、信息论和加密硬件的多种安全方案,实现了安全和性能之间的平衡。在满足不同合规政策的前提下,实现联合建模的隐私计算技术应用。
易用
提供交互式编程、高阶API封装和对常用机器学习库集成的功能。具有开箱即用的能力和接近中心化数据建模的流程体验。支持模型开发快速上手,帮助用户高效完成模型研发。
高性能
针对多个参与方可能出现的高延迟、低带宽问题,产品在通信机制上进行了优化,如采用模型/梯度稀疏化的方案,实现了对大规模、分布式模型训练的可靠支持。针对部分数据异构和算力异构的问题,则采用了 client 模型个性化算法,优化和提高了算法的性能。
可扩展
本产品和蚂蚁隐私计算服务平台其他产品使用同一套核心资源管理平台及系统框架,可根据现场实际环境组装产品功能,准确制定完整的解决方案。
应用场景
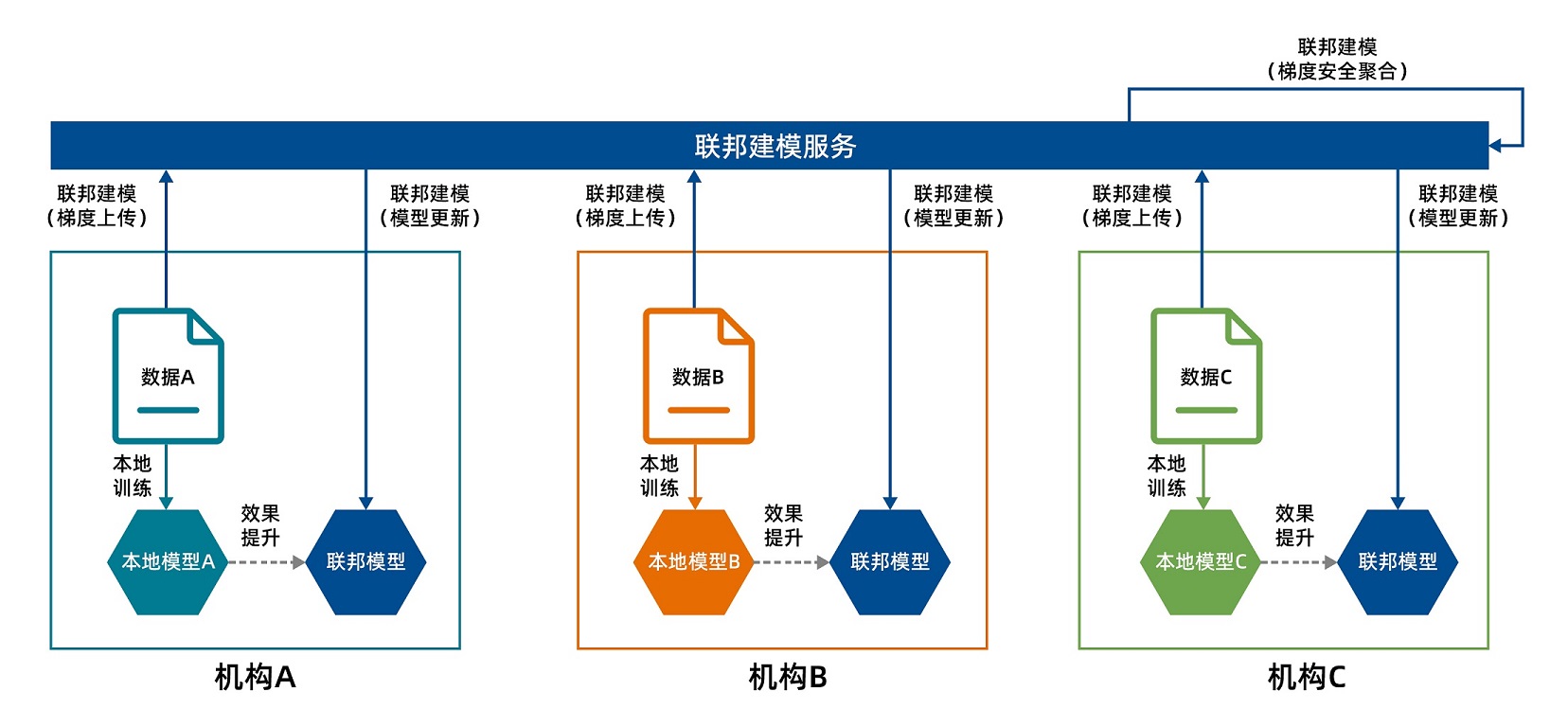
多家机构拥有结构相似、内容不同的数据,并且这些机构都需要使用各自的数据创建机器学习模型。多家机构使用联邦建模服务共同创建的机器学习模型,即联邦模型,该机器学习模型的效果会优于只用一部分数据创建的机器学习模型。若机构在满足数据合规政策时,被要求原始数据不能出域,则联邦建模可以采用数据不动模型动的方式,让各参与方获取效果更优的机器学习模型。在保障建模的原始数据及中间信息安全的前提下,让各参与方共享数据价值的增益。以下是多家机构共同参与使用联邦建模服务的示意图。