联邦建模概述
更新时间:
联邦建模控制台是进行联邦学习的模型开发平台。服务对象为联邦模型的开发人员,如联邦算法工程师。
联邦建模控制台封装了联邦学习的基础能力,并且集成了常用机器学习库的功能,如 TensorFlow,具有开箱即用的能力。因此您只需专注于模型本身,无需关注联邦算法的实现细节,以便快速高效地完成模型开发。在脚本开发过程中,您需要通过新建脚本、编辑脚本、执行脚本完成联邦建模。根据联邦建模的不同开发阶段,将脚本分为 5 种类型:联邦表、预处理规则、预处理应用、模型训练、模型评估,具体请参见 脚本输入/输出配置说明。一个完整的联邦学习项目中包含多种类型的脚本,脚本与脚本之间,通过输入、输出/产出的数据进行关联,如下图所示。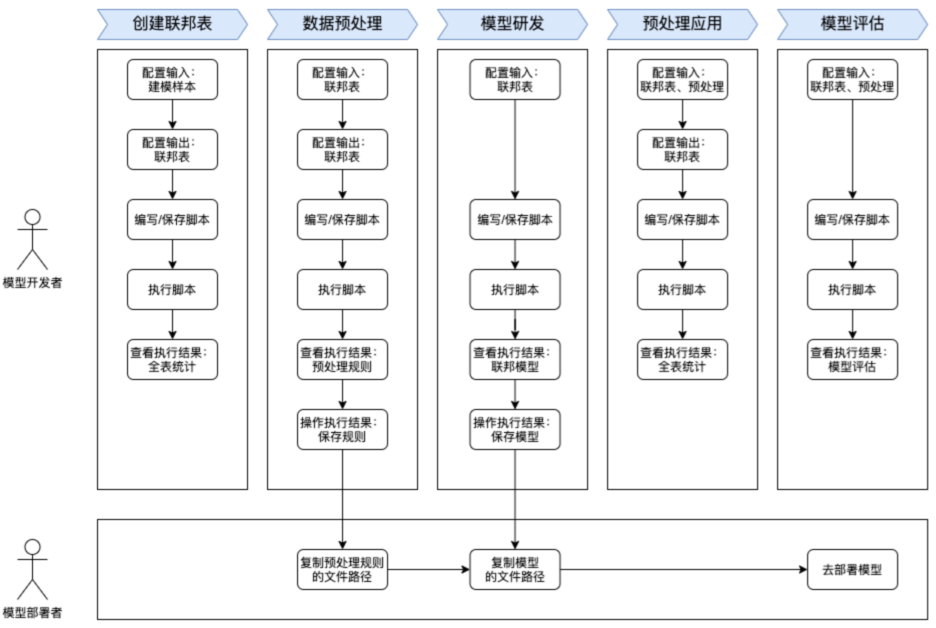 联邦模型开发分为:
联邦模型开发分为:
数据处理:包含样本数据处理和联邦数据处理。
样本数据处理:将各节点中具有相同属性的数据逻辑集合起来,即创建联邦表。
联邦数据处理:对联邦表中的数据进行预处理,包括数据预处理和预处理应用。
模型训练:使用预处理过的训练集数据训练模型。
模型评估:使用预处理过的测试集数据评估模型效果。
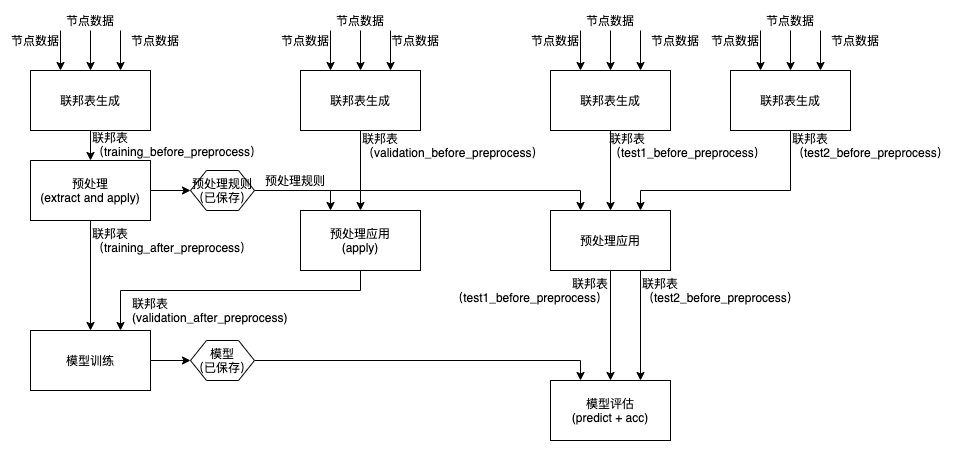
典型的模型开发业务逻辑如下图所示,其中,离线样本生成的三种联邦表分别以训练集、验证集和测试集作为预处理、预处理应用和模型评估的输入。
该文章对您有帮助吗?