本文为您介绍如何使用数据传输同步 OceanBase 数据库的数据至 Kafka。
背景信息
Kafka 是目前广泛应用的高性能分布式流计算平台,数据传输支持 OceanBase 数据库两种租户与自建 Kafka 数据源之间的数据实时同步,扩展消息处理能力,广泛应用于实时数据仓库搭建、数据查询和报表分流等业务场景。
前提条件
数据传输已具备云资源访问权限。详情请参见 数据传输迁移角色授权。
已为源端 OceanBase 数据库创建专用于数据同步任务的数据库用户,并为其赋予了相关权限。详情请参见 创建数据库用户。
使用限制
数据同步的对象仅支持物理表,不支持其他对象。
数据传输支持的 Kafka 版本为 V0.9、V1.0 和 V2.x。
数据同步过程中,如果您在源端修改了同步范围内的表名称,且重命名后的名称不在同步对象中,则该部分数据将不被同步至目标 Kafka 实例中。
待同步的表名和其中的列名不能包含中文字符。
数据传输仅支持迁移库名、表名和列名为 ASCII 码且不包含特殊字符(包括换行、空格,以及 .|"'`()=;/&\)的对象。
数据传输不支持 OceanBase 备库作为源端。
注意事项
在源端为 OceanBase 数据库并开启同步 DDL 的数据同步任务中,如果源端库表发生重命名(
RENAME)操作,建议您重新启动任务,避免增量同步丢失数据。当 OceanBase 数据库为 V4.0.0 ~ V4.3.x 之间的版本(V4.2.5 BP1 除外),并且选择了增量同步时,请为生成列配置 STORED 属性。否则增量日志中将不保存生成列的信息,可能导致增量同步数据异常的问题。
当更新的行包括 LOB 列时:
如果 LOB 列为更新列,请勿依赖 LOB 列在
UPDATE或DELETE操作前的值。目前使用 LOB 列进行存储的数据类型包括 JSON、GIS、XML、UDT(用户定义类型),以及 LONGTEXT、MEDIUMTEXT 等各类 TEXT。
如果 LOB 列为非更新列,则在
UPDATE或DELETE操作前或操作后,LOB 列的值均为 NULL。
节点之间的时钟不同步,或者电脑终端和服务器之间的时钟不同步,均可能导致增量同步的延迟时间不准确。
例如,如果时钟早于标准时间,可能导致延迟时间为负数。如果时钟晚于标准时间,可能导致延迟问题。
当任务意外中断进行断点续传时,Kafka 实例中可能会存在部分重复数据(最近一分钟内),因此下游系统需要具备去重能力。
同步 OceanBase 数据库的数据至 Kafka 时,源端执行创建唯一索引语句失败,Kafka 会消费到创建 DDL 语句和删除 DDL 语句。如果传到下游的创建索引 DDL 执行失败,请忽略该异常。
如果在创建数据同步任务时,您仅配置了 增量同步,数据传输要求源端数据库的本地增量日志保存 48 小时以上。
如果在创建数据同步任务时,您配置了 全量同步+增量同步,数据传输要求源端数据库的本地增量日志至少保留 7 天以上。否则数据传输可能因无法获取增量日志而导致数据同步任务失败,甚至导致源端和目标端数据不一致。
支持的源端和目标端实例类型
下表中,OceanBase 数据库 MySQL 租户简称为 OB_MySQL,OceanBase 数据库 Oracle 租户简称为 OB_Oracle。
源端 | 目标端 |
OB_MySQL(OceanBase 集群实例) | Kafka(阿里云 Kafka 实例) |
OB_MySQL(OceanBase 集群实例) | Kafka(VPC 内自建 Kafka 实例) |
OB_MySQL(OceanBase 集群实例) | Kafka(公网 Kafka 实例) |
OB_MySQL(Serverless 实例) | Kafka(阿里云 Kafka 实例) |
OB_MySQL(Serverless 实例) | Kafka(VPC 内自建 Kafka 实例) |
OB_MySQL(Serverless 实例) | Kafka(公网 Kafka 实例) |
OB_Oracle(OceanBase 集群实例) | Kafka(阿里云 Kafka 实例) |
OB_Oracle(OceanBase 集群实例) | Kafka(VPC 内自建 Kafka 实例) |
OB_Oracle(OceanBase 集群实例) | Kafka(公网 Kafka 实例) |
同步 DDL 支持的范围
创建表
CREATE TABLE重要创建的表需要在同步对象范围之内。目前仅支持对已经同步的表进行
DROP TABLE操作后,再执行CREATE TABLE。修改表
ALTER TABLE删除表
DROP TABLE清空表
TRUNCATE TABLE说明延迟删除场景下,同一个事务中会有两条一样的
TRUNCATE TABLEDDL。此时,下游消费需要按幂等方式处理。从指定的分区中删除数据
ALTER TABLE…TRUNCATE PARTITION创建索引
CREATE INDEX删除索引
DROP INDEX添加表的备注
COMMENT ON TABLE表重命名
RENAME TABLE重要重命名后的表名需要在同步对象范围之内。
操作步骤
登录 OceanBase 管理控制台,购买数据同步任务。
详情请参见 购买数据同步任务。
在 数据传输 > 数据同步 页面,单击新购买的数据同步任务后的 配置。

如果您需要引用已有的任务配置信息,可以单击 引用配置。详情请参见 引用和清空数据同步任务配置。
在 选择源和目标 页面,配置各项参数。
参数
描述
同步任务名称
建议使用中文、数字和字母的组合。名称中不能包含空格,长度不能超过 64 个字符。
源端
如果您已新建 OceanBase 数据源,请从下拉列表中进行选择。如果未新建,请单击下拉列表中的 新建数据源,在右侧对话框进行新建。参数详情请参见 新建 OceanBase 数据源。
重要源端不支持 OceanBase 数据库的 实例类型 为 OceanBase 租户实例。
目标端
如果您已新建 Kafka 数据源,请从下拉列表中进行选择。如果未新建,请单击下拉列表中的 新建数据源,在右侧对话框进行新建。参数详情请参见 新建 Kafka 数据源。
标签(可选)
单击文本框,在下拉列表中选择目标标签。您也可以单击 管理标签,进行新建、修改和删除。详情请参见 通过标签管理数据同步任务。
单击 下一步。在 选择同步类型 页面,选择当前数据同步任务的同步类型。
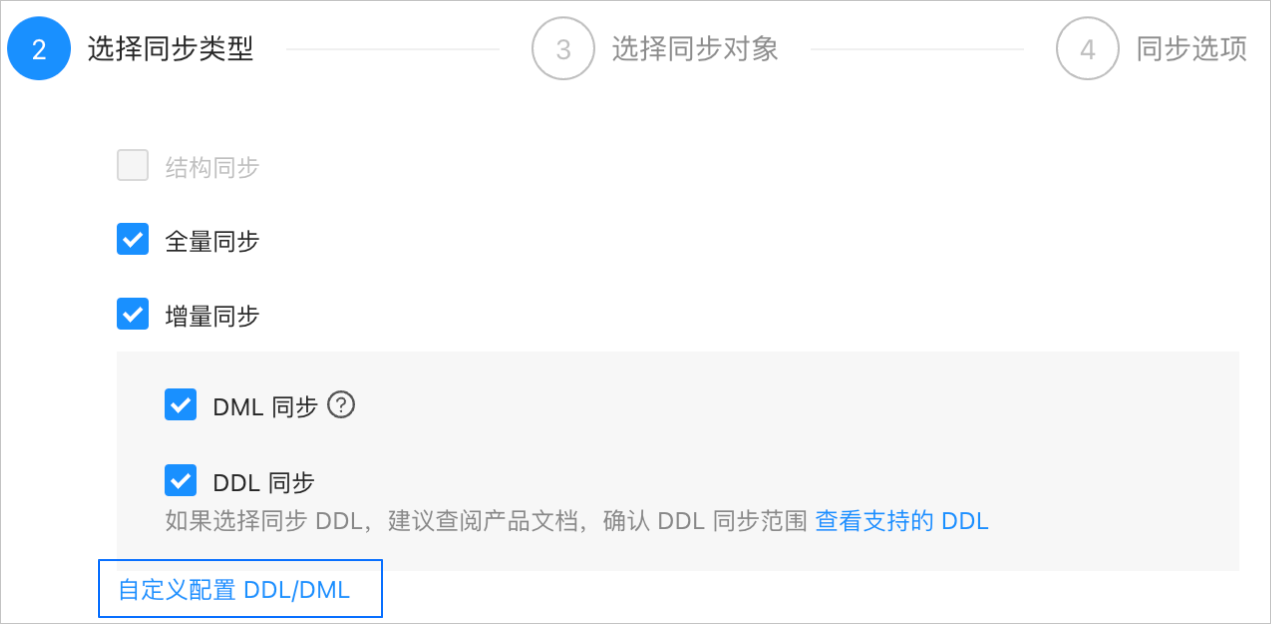
同步类型包括 全量同步 和 增量同步。增量同步 支持 DML 同步(包括
INSERT、DELETE和UPDATE)和 DDL 同步,您可以根据需求进行自定义配置。详情请参见 自定义配置 DDL/DML。单击 下一步。在 选择同步对象 页面,选择当前数据同步任务需要同步的对象。
您可以通过 指定对象 和 匹配规则 两个入口选择同步对象。本文为您介绍通过 指定对象 方式选择同步对象的具体操作,配置匹配规则的详情请参见 配置和修改匹配规则 中库到消息队列的通配规则说明和配置方式。
说明如果您在 选择同步类型 步骤已勾选 DDL 同步,建议通过匹配规则方式选择同步对象,以确保所有符合同步对象规则的新增对象都将被同步。如果您通过指定对象方式选择同步对象,则新增对象或重命名后的对象将不会被同步。
同步 OceanBase 数据库的数据至 Kafka 时,支持多表到多 Topic 的同步。
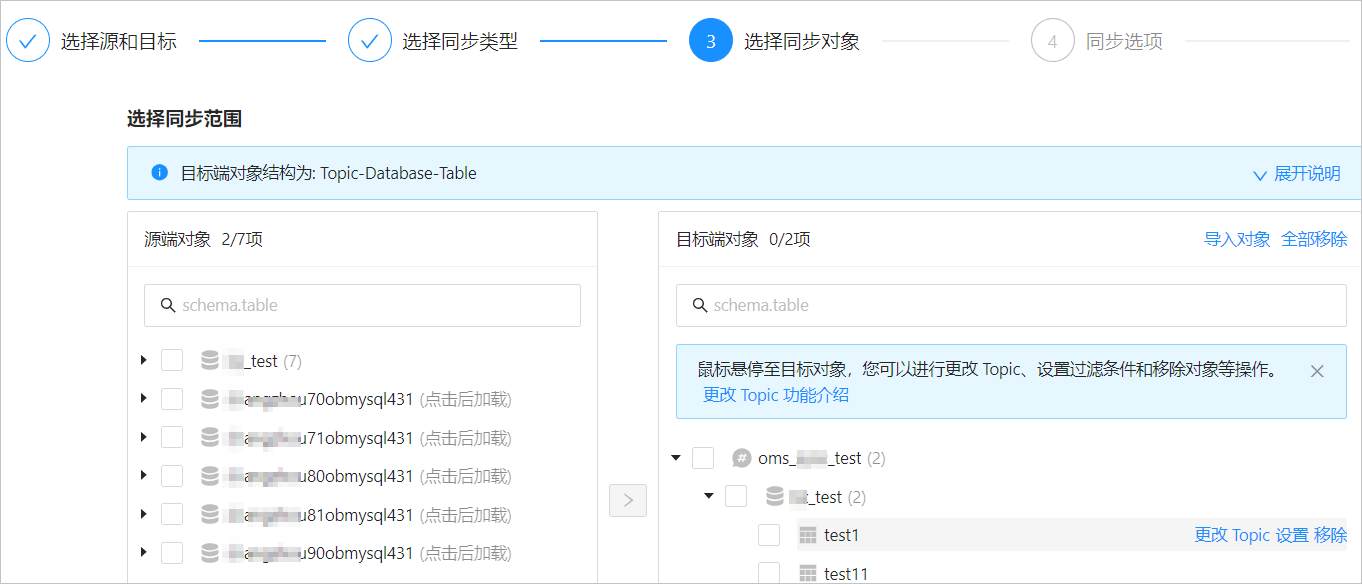
在 选择同步对象 区域,选中 指定对象。
在选择区域左侧选中需要同步的对象。
单击 >。
在 将对象映射至 Topic 对话框的 已有 Topic 下拉列表中,搜索并选中需要同步的 Topic。
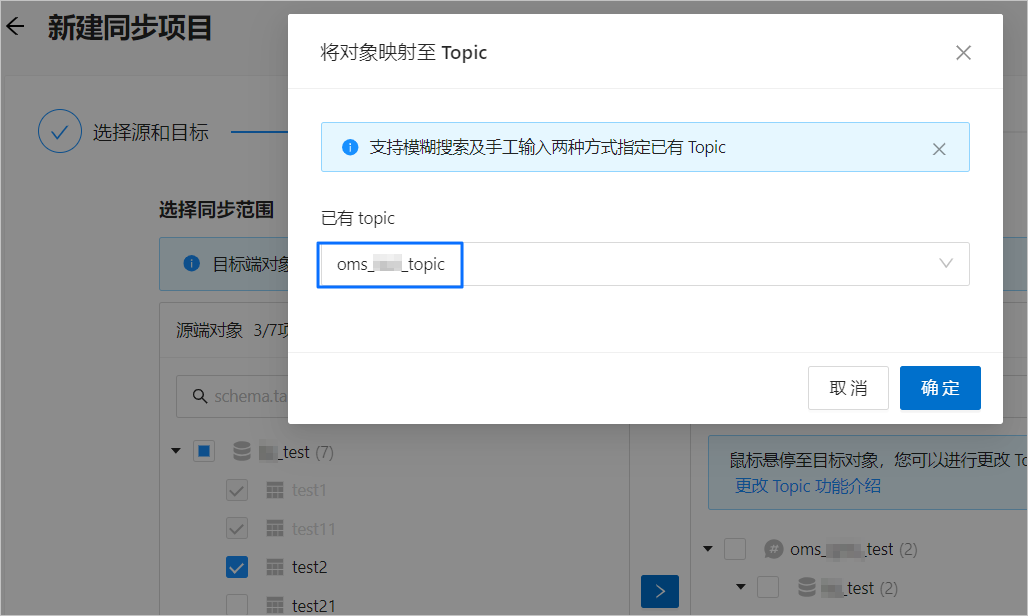
单击 确定。
数据传输支持通过文本导入对象,并支持对目标端对象进行更改 Topic、设置行过滤、移除单个对象或全部对象等操作。目标端对象的结构为 Topic>Database>Table。
说明通过 匹配规则 方式选择同步对象时,重命名能力由匹配规则语法覆盖,操作处仅支持设置过滤条件,以及选择分片列和需要同步的列。详情请参见 配置和修改匹配规则。
操作
描述
导入对象
在选择区域的右侧列表中,单击右上角的 导入对象。
在对话框中,单击 确定。
重要导入会覆盖之前的操作选择,请谨慎操作。
在 导入同步对象 对话框中,导入需要同步的对象。 您可以通过导入 CSV 文件的方式进行设置行过滤条件、设置过滤列和设置分片列等操作。详情请参见 下载和导入同步对象配置。
单击 检验合法性。
通过合法性的检验后,单击 确定。
更改 Topic
数据传输支持对目标对象进行更改 Topic 操作。详情请参见 更改 Topic。
设置
数据传输支持
WHERE条件实现行过滤,并选择分片列和需要同步的列。在 设置 对话框中,您可以进行以下操作。
在 行过滤条件 区域的文本框中,输入标准的 SQL 语句中的
WHERE子句,来配置行过滤。详情请参见 SQL 条件过滤数据。在 分片列 下拉列表中,选择目标分片列。您可以选择多个字段作为分片列,该参数为可选参数。
选择分片列时,如果没有特殊情况,默认选择主键即可。如果存在主键负载不均衡的情况,请选择唯一性标识且负载相对均衡的字段作为分片列,避免潜在的性能问题。分片列的主要作用如下:
负载均衡:在目标端可以进行并发写入的情况下,通过分片列区分发送消息需要使用的特定线程。
有序性:由于存在并发写入可能导致的无序问题,数据传输确保在分片列的值相同的情况下,用户接收到的消息是有序的。此处的有序是指变更顺序(DML 对于一列的执行顺序)。
在 选择列 区域,选择需要同步的列。详情请参见 列过滤。
移除/全部移除
数据传输支持在数据映射时,对暂时选中到目标端的单个或多个对象进行移除操作。
移除单个同步对象
在选择区域的右侧列表中,鼠标悬停至目标对象,单击显示的 移除,即可移除该同步对象。
移除全部同步对象
在选择区域的右侧列表中,单击右上角的 全部移除。在对话框中,单击 确定,即可移除全部同步对象。
单击 下一步。在 同步选项 页面,配置各项参数。
全量同步
在 选择同步类型 页面,选中 全量同步,才会显示下述参数。
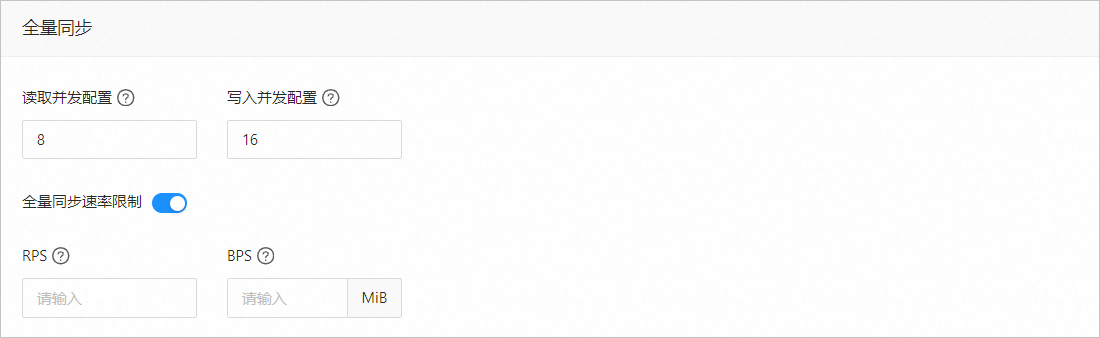
参数
描述
读取并发配置
该参数用于配置全量同步阶段从源端读取数据的并发数,最大限制为 512.并发数过高可能会造成源端压力过大,影响业务。
写入并发配置
该参数用于配置全量同步阶段往目标端写入数据的并发数,最大限制为 512。并发数过高可能会造成目标端压力过大,影响业务。
全量同步速率限制
您可以根据实际需求决定是否开启全量同步速率限制。如果开启,请设置 RPS(全量同步阶段每秒最多可以同步至目标端的数据行数的最大值限制)和 BPS(全量同步阶段每秒最多可以同步至目标端的数据量的最大值限制)。
说明此处设置的 RPS 和 BPS 仅作为限速限流能力,全量同步实际可以达到的性能受限于源端、目标端、实例规格配置等因素的影响。
增量同步
在 选择同步类型 页面,选中 增量同步,才会显示下述参数。
参数
描述
写入并发配置
该参数用于配置增量同步阶段往目标端写入数据的并发数,最大限制为 512。并发数过高可能会造成目标端压力过大,影响业务。
增量同步速率限制
您可以根据实际需求决定是否开启增量同步速率限制。如果开启,请设置 RPS(增量同步阶段每秒最多可以同步至目标端的数据行数的最大值限制)和 BPS(增量同步阶段每秒最多可以同步至目标端的数据量的最大值限制)。
说明此处设置的 RPS 和 BPS 仅作为限速限流能力,增量同步实际可以达到的性能受限于源端、目标端、实例规格配置等因素的影响。
增量同步起始位点
如果选择同步类型时已选择 全量同步,则不支持修改该参数。
如果选择同步类型时未选择 全量同步,但选择了 增量同步,请在此处指定同步某个时间节点之后的数据,默认为当前系统时间。详情请参见 设置增量同步位点。
高级选项

参数
描述
序列化方式
控制数据同步至 Kafka 的消息格式,目前支持 Default、Canal、DataWorks(支持 V2.0)、SharePlex、 DefaultExtendColumnType、Debezium、DebeziumFlatten、DebeziumSmt 和 Avro。详情请参见 数据格式说明。
重要目前仅 OceanBase 数据库 MySQL 租户支持 Debezium、DebeziumFlatten、DebeziumSmt 和 Avro。
当选择 DataWorks 时,同步 DDL 不支持
COMMENT ON TABLE和ALTER TABLE…TRUNCATE PARTITION。
分区规则
同步 OceanBase 数据库的数据至 Kafka Topic 的规则,目前支持 Hash、Table 和 One。不同场景下的 DDL 语句投递和示例,请参见表格下方的说明。
Hash 表示数据传输使用一定的 Hash 算法,根据主键值或分片列值 Hash 选择 Kafka Topic 的分区。
Table 表示数据传输将一张表中的全部数据投递至同一个分区中,以表名作为 Hash 键。
One 表示 JSON 消息会投递至 Topic 下的某个分区,目的是为了保持排序。
业务系统标识(可选)
仅选择 序列化方式 为 DataWorks 时,会显示该参数,用于标识数据的业务系统来源,以便您后续进行自定义处理。该业务系统标识的长度限制为 1~20 个字符。
下表为不同场景的 DDL 语句投递说明。
分区规则
DDL 语句涉及多张表
(例如 RENAME TABLE)
DDL 语句无法确认相关表
(例如 DROP INDEX)
DDL 语句涉及单张表
Hash
DDL 语句投递至相关表所在 Topic 的所有分区。
例如,DDL 语句涉及 A、B 和 C 三张表,如果 A 在 Topic 1、B 在 Topic 2、C 不在本任务中,则该 DDL 语句投递至 Topic 1 和 Topic 2 下的所有分区。
DDL 语句投递至本任务所有 Topic 的所有分区。
例如,DDL 语句无法被数据传输识别,如果当前任务存在三个 Topic,则该 DDL 语句被投递至这三个 Topic 的所有分区。
DDL 语句投递至该表所属 Topic 下的所有分区。
Table
DDL 语句投递至相关表所在 Topic 的对应表名 Hash 值所在的分区。
例如,DDL 语句涉及 A、B 和 C 三张表,如果 A 在 Topic 1、B 在 Topic 2、C 不在本任务中,则该 DDL 语句投递至 Topic 1 和 Topic 2 下相关表 Hash 值所在的分区。
DDL 语句投递至本任务所有 Topic 的所有分区。
例如,DDL 语句无法被数据传输识别,如果本任务存在三个 Topic,则该 DDL 语句被投递至这三个 Topic 的所有分区。
根据 Table Name 进行 Hash,投递至该表所属 Topic 内的某个分区。
One
DDL 语句投递至相关表所在 Topic 的固定分区。
例如,DDL 语句涉及 A、B 和 C 三张表,如果 A 在 Topic 1、B 在 Topic 2、C 不在本任务中,则该 DDL 语句投递至 Topic 1 和 Topic 2 下的某个固定分区。
DDL 语句投递至本任务所有 Topic 的某个固定分区。
例如,DDL 语句无法被数据传输识别,如果本任务存在三个 Topic,则该 DDL 语句被投递至这三个 Topic 的某个固定分区。
DDL 语句投递至该表所属 Topic 下的某个固定分区。
单击 预检查。
在 预检查 环节,数据传输会检测源端和目标端的连接情况。如果预检查报错:
您可以在排查并处理问题后,重新执行预检查,直至预检查成功。
您也可以单击错误预检查项操作列中的 跳过,会弹出对话框提示您跳过本操作的具体影响,确认可以跳过后,请单击对话框中的 确定。
预检查成功后,单击 启动任务。
如果您暂时无需启动任务,请单击 保存。后续您只能在 同步任务列表 页面手动启动任务或通过批量操作启动任务。批量操作的详情请参见 批量操作数据同步任务。
数据传输支持在数据同步任务运行过程中修改同步对象,详情请参见 查看和修改同步对象及其过滤条件。数据同步任务启动后,会根据选择的同步类型依次执行,详情请参见 查看同步详情。
如果数据同步任务运行报错(通常由于网络不通或进程启动过慢导致),您可以在数据同步任务的列表或详情页面,单击 恢复。