V4.0.0是Quick Audience的重磅升级版本。
V4.0.0的重要改进之一,是在导入数据时增加ID-Mapping过程,将来源于不同渠道的原始用户数据,通过手机号码进行用户身份识别、去重,在经过计算整合后,给用户赋予Quick Audience中唯一的系统ID,如下图所示。
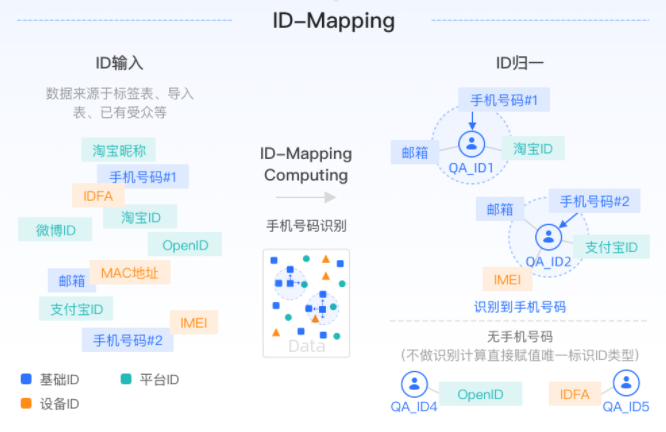
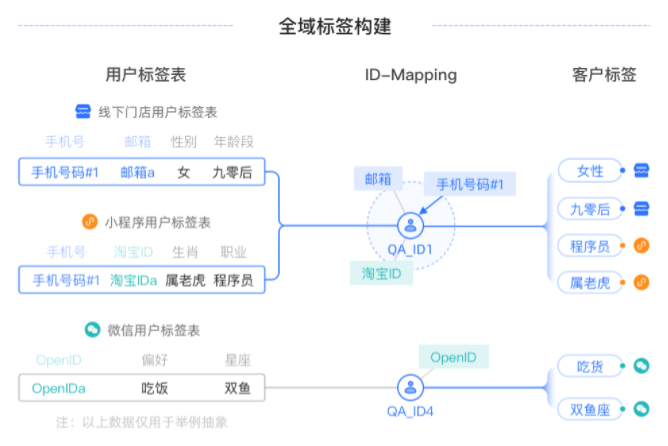
在后续的用户分析、受众筛选等操作中,系统ID将作为用户的唯一标识。因此,不论用户或受众来自哪个表,均通过其系统ID去匹配所有ID类型和标签、行为等数据,实现全渠道数据整合,最终构建一个全域标签系统。
迁移
新版与老版使用同一个组织、空间、账号系统,您无需再次进行组织、空间、账号配置。
新版与老版使用不同的数据存储体系,老客户首次使用新版时,需要按新版的用户指南操作说明,重新添加数据源、导入数据、创建RFM/AIPL模型、受众、营销任务等。
数据要求
数据表格式要求请参见数据表样例。请按照新的数据要求进行调整,确保可用。
新版支持的表类型与旧版支持的数据集底表类型对应关系如下表所示。旧版的用户标签数据集、行为数据集、RFM模型底表可以在调整格式后使用于新版;但旧版的AIPL模型底表不可用于新版,新版的AIPL模型将使用用户行为表数据。
新版数据表类型 | 旧版数据集底表类型 |
|---|---|
用户标签表 | 用户标签表 |
用户行为表 | 用户行为表 |
订单汇总表 | RFM模型表——客户数据 |
订单明细表 | RFM模型表——交易数据 |
统计表 | - |
- | AIPL模型表 |
功能差异
V4.0.0在功能用法上进行了一些改进,以下列出几个较大的功能差异点,产品详细功能请参见V4.0.0用户指南。
差异点 | V4.0.0 | 改版前 |
|---|---|---|
数据源 | 计算源+分析源 | 数据源 |
数据形态 | 计算源表→导入到分析源→生成标签模型/AIPL模型/RFM模型/受众 | 数据源表→生成数据集/AIPL模型/RFM模型→生成受众 |
用户身份识别 | 数据导入时进行用户身份识别,赋予唯一的系统ID。后续分析、推送、营销等操作涉及用户ID、标签时,通过用户的系统ID匹配到的任何来源表的ID、标签均可以用于分析、推送、营销。 | 不进行用户身份识别。不同渠道数据源表的用户信息割裂,无法协作。 |
受众筛选 | 支持多维度联合筛选,不同维度之间通过交并差计算自由组合。受众交并无上限。 | 不同维度之间仅支持通过交并计算组合,且仅能同时使用交/并。受众交并最多支持3层。 |
标签多分支组件 | 标签多分支支持根据用户的多维度特征筛选分支:标签、AIPL模型、RFM模型、行为、统计指标、在指定受众中。 | 标签多分支仅支持根据用户标签筛选分支。 |
用户指南
单击下载独立部署V4.0.0用户指南。