云原生数据湖分析(DLA)产品已下线,云原生数据仓库 AnalyticDB MySQL 版湖仓版支持DLA已有功能,并提供更多的功能和更好的性能。AnalyticDB for MySQL相关使用文档,请参见什么是云原生数据仓库AnalyticDB MySQL版。
云原生数据湖分析(简称DLA)是新一代大数据解决方案,采取计算与存储完全分离的架构,支持数据库(RDS\PolarDB\NoSQL)与消息实时归档建仓,提供弹性的Spark与Presto,满足在线交互式查询、流处理、批处理、机器学习等诉求,也是传统Hadoop方案上云的有竞争力的解决方案。DLA的方案架构图如下所示: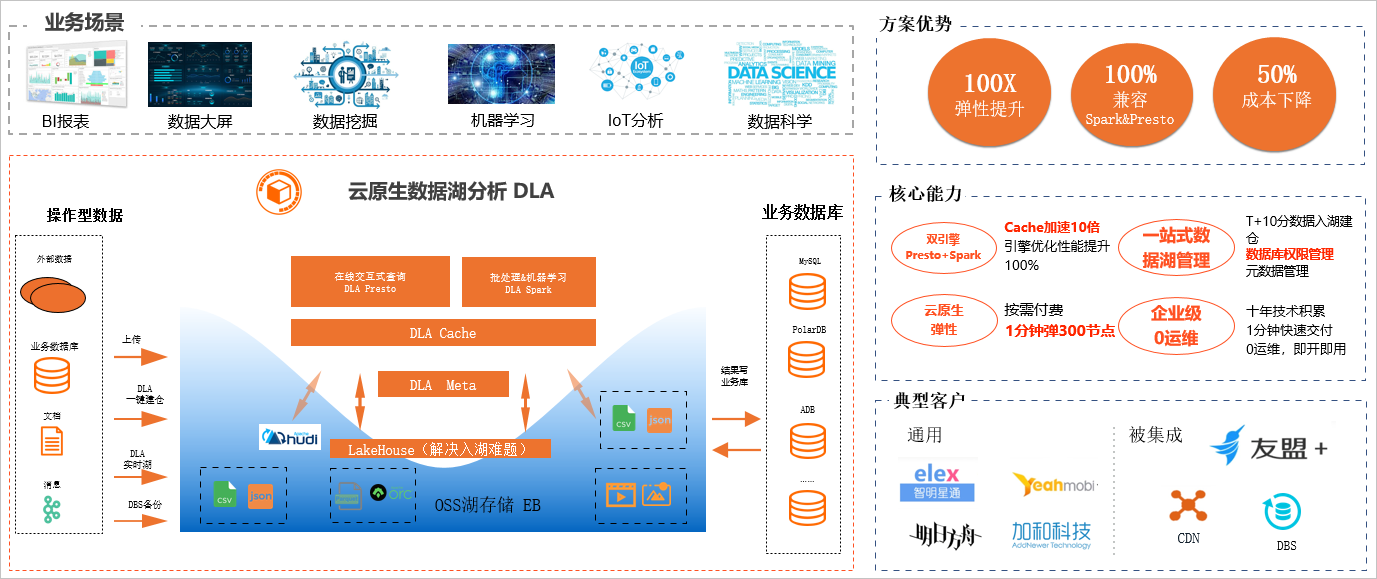
DLA提供扫描量版本与CU版本的计费模式,其中扫描量版本支持Presto引擎,CU版本支持Presto与Spark引擎,具体请参见扫描量版本与CU版本的差异。
DLA支持的数据源
DLA支持的数据源矩阵,具体请参见数据源与功能的矩阵。
数据源 | Serverless Presto | Serverless Spark |
支持 | 支持 | |
支持 | 支持 | |
支持 | 支持 | |
待支持 | 支持 | |
待支持 | 支持 | |
支持 | 待支持 | |
支持 | 支持 | |
支持 | 支持 | |
支持 | 支持 | |
支持 | 支持 | |
支持 | 支持 | |
支持 | 支持 | |
支持 | 支持 | |
Kudu | 支持 | 支持 |
支持 | 支持 |
何时使用DLA
DLA主要围绕数据湖存储OSS提供一站式的云原生数据湖分析与计算方案,如果您有如下的痛点可以使用DLA:
寻求一站式的数据湖解决方案,从数据高效入湖、数据的ETL、机器学习、交互式分析。DLA提供了数据湖构建、Presto&Spark引擎。
寻求安全的数据处理解决方案。DLA所有的库表及存储的数据都有一整套安全的方案,避免数据被误用。
寻求低成本的数据处理方案。DLA方案是完全Serverless的解决方案,是阿里云提供的云原生的数据处理方案。
从之前Hadoop体系过渡到数据湖方案。DLA提供与Hadoop体系兼容的过渡方案。
为什么同时支持Serverless Presto与Serverless Spark?
DLA Serverless Presto是在开源Apache Presto基础上研发,完全由内存完成计算工作,具备高性能、交互式的分析体验,秒级可返回;DLA Serverless Spark是在开源Apache Spark基础上研发,兼容Apache Spark所有的API。
以下场景推荐您使用DLA Serverless Spark:
需要自定义Code,SQL很难表达的,例如编写Java、Scala、Python或者SQL带条件的。
需要大规模的清洗,例如1天清洗OSS 1 TB~1 PB的数据。
需要算法支持,DLA Spark支持完整的Spark算法库。
需要支持Streaming。