云原生数据湖分析DLA(Data Lake Analytics)是新一代大数据解决方案,采取计算与存储完全分离的架构,支持数据库与消息实时归档建仓。DLA提供弹性的Spark与Presto,满足在线交互式查询、流处理、批处理、机器学习等诉求,也是传统Hadoop方案上云的有竞争力的解决方案,其中弹性是DLA最为核心的竞争力。
弹性能力
Spark CU版弹性:按照Job实际使用弹出资源,只对实际运行的资源进行计费,比传统方案节约50%+的成本。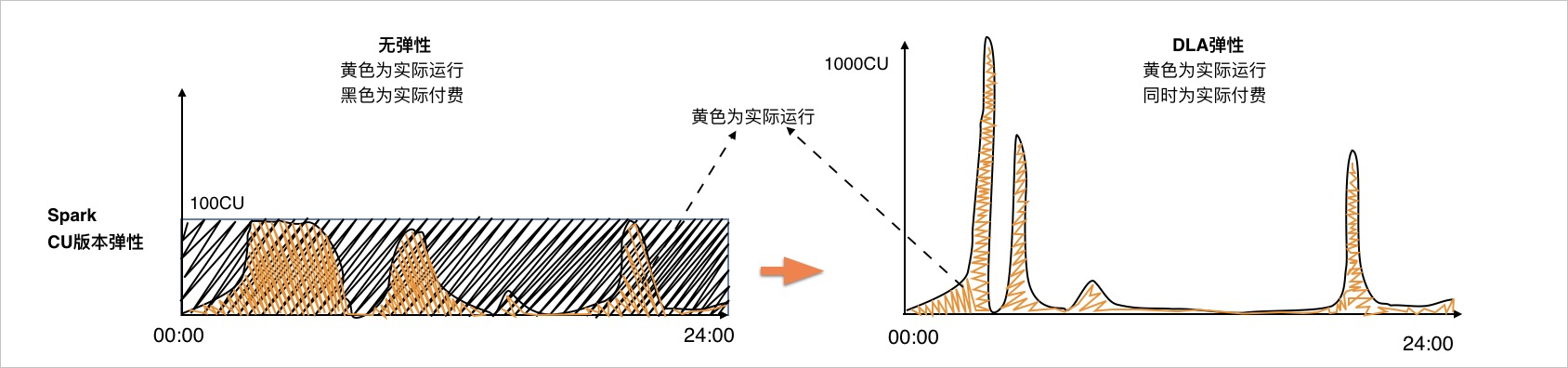
Presto CU版弹性:分时弹性(设置时间段来使用CU资源)。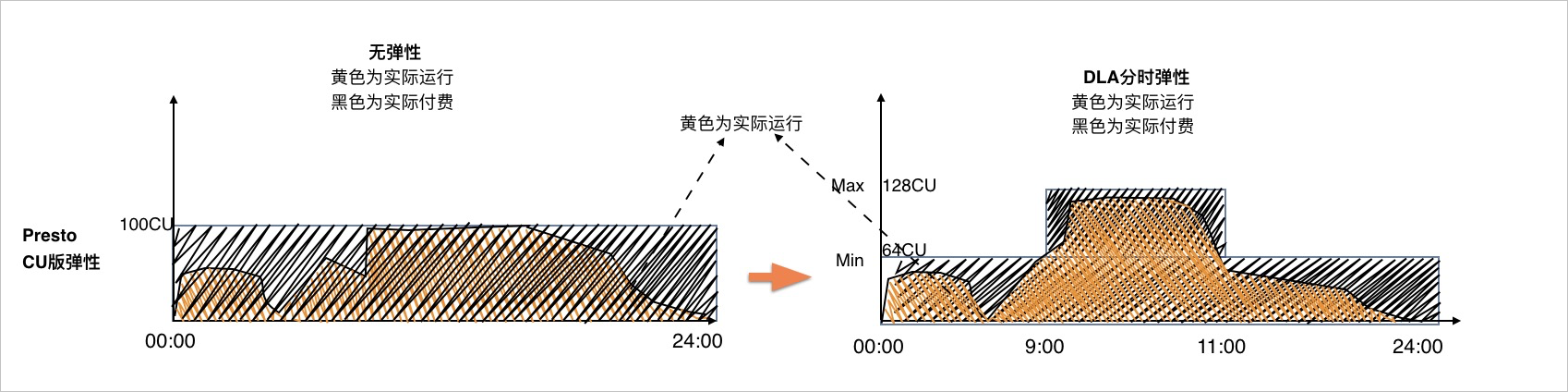
Presto扫描量版本:按照扫描量计费,只对实际运行的SQL进行计费。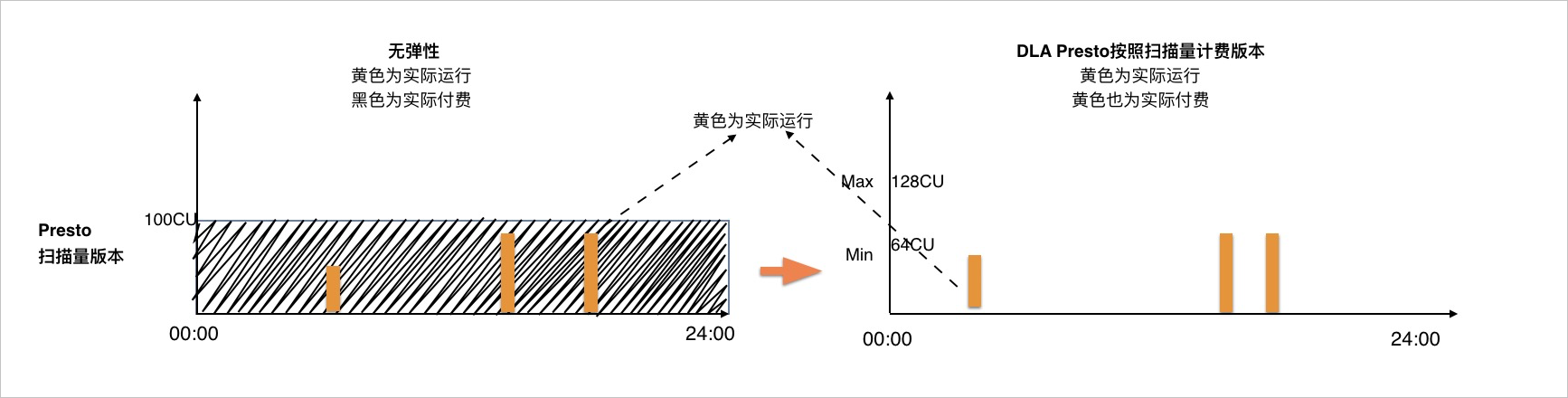
优势总结
| 对比类目 | 自建Hadoop系统 | 阿里云 DLA + OSS方案 |
|---|---|---|
| 产品体系 | 复杂、组件较多 | 一体化、端到端(入湖=>管理=>ETL =>分析查询),产品体验好;组件精耕细作Presto、Spark; |
| 弹性 | 无 | 云原生、弹性强、一分钟可弹300节点参与计算 |
| 性价比 | 开源方案 | 内置大量优化+弹性,比开源自建集群至少降低50%+的成本 |
| DB&消息(如Kafka)归档到Hudi(存储在OSS) | 无或者自己写Code | 链路大量优化、Hudi大量优化,产品化支持(实现中) |
| 学习与运维成本 | 高(需要较长时间搭建、配置、运维、学习) | 低(即开即用、零运维成本) |
| 安全、多租户 | 基于 Kerberos&Ranger,较为复杂 | 支持数据库模式库、表授权模式,多租户 |
| 功能 | 开源功能,缺乏云连接器的支持,云内部系统对接与优化 | 针对阿里云OSS & OTS &ADB 等数据源深度优化,Presto与Spark内核大量优化 |