DLA Lakehouse实时入湖方案利用数据湖技术,重构数仓语义;分析数据湖数据,实现数仓的应用。本文以RDS MySQL数据源为例介绍了RDS MySQL从入湖到分析的操作步骤。
背景信息
数据湖分析(Data Lake Analytics)是⽬前炙⼿可热的⽅向,主要是以对象存储系统为核心,构建海量、低成本的结构化、半结构化、⾮结构化对象⽂件的入湖、存储和分析业务。⽬前各⼤云⼚商都在积极跟进,布局相关的业务能力,阿⾥云数据湖分析团队在这个⽅向也很早就投⼊相关产品的研发。随着数据湖的应⽤越来越多,⼤家发现依赖数据湖最原始的能力,仅仅做简单的存储和分析,往往会遇到很多的问题。比较典型的痛点如下:
- 多源头数据需要统⼀存储管理,并需要便捷的融合分析。
- 源头数据元信息不确定或变化大,需要⾃动识别和管理;简单的元信息发现功能时效性不够。
- 全量建仓或直连数据库进行分析对源库造成的压⼒较大,需要卸载线上压⼒规避故障。
- 建仓延迟较⻓(T+1天),需要T+10m的低延迟入湖。
- 更新频繁致小文件多,分析性能差,需要Upsert⾃动合并。
- 海量数据在事务库或传统数仓中存储成本高,需要低成本归档。
- 源库⾏存储格式或非分析型格式,分析能力弱,需要⽀持列式存储格式。
- ⾃建⼤数据平台运维成本高,需要产品化、云原生、⼀体化的⽅案。
- 常见数仓的存储不开放,需要⾃建能力、开源可控。
Lakehouse是一种更先进的范式(Paradigm)和方案,用来解决上述简单入湖分析遇到的各种痛点问题。在Lakehouse技术中,⾮常关键的技术就是多版本的⽂件管理协议,它提供⼊湖和分析过程中的增量数据实时写⼊、ACID事务和多版本、小⽂件⾃动合并优化、元信息校验和⾃动进化、⾼效的列式分析格式、⾼效的索引优化、超⼤分区表存储等能⼒。⽬前开源社区有Hudi、Delta、Iceberg等数据湖方案,阿⾥云数据湖分析团队选择了比较成熟的Hudi作为DLA Lakehouse的湖仓⼀体化格式。关于Lakehouse的更多介绍,请参见Lakehouse介绍。
DLA Lakehouse核心概念和相关约束说明
- Lakehouse(湖仓)有两重含义:
- 范式:即解决简单⼊湖分析所遇到的痛点问题的⼀种解决⽅案。
- 存储空间:⽤来提供⼀个从其他地⽅入湖写⼊数据的空间,后续所有相关操作都围绕着这个湖仓来进行。
- 不同的Lakehouse有完全不同的路径,路径之间不可以相互有前缀关系(防止数据覆盖)。
- Lakehouse不能轻易进行修改。
- Workload(⼯作负载)是围绕湖仓⼀体化而展开的核心工作的编排调度(由DLA Lakehouse统⼀调度),包括如下功能特点:
- 入湖建仓
- 为了将其他源头的数据,汇总到整个湖仓内构建⼀个统⼀的数据平台,例如有DB类型的⼊湖建仓,也有Kafka的入湖建仓,还有OSS的数据转换建仓。
- 不同的入湖建仓,涉及到全量、增量等多个阶段,会统⼀编排并统⼀协调调度,简化⽤户管理成本。
- 查询优化
为了提升分析能力,构建各种查询优化方面的工作负载,比如自动构建索引、自动清理历史数据、自动构建物化视图等。
- 管理
- 成本优化:⾃动⽣命周期、冷热分层存储等。
- 数据互通:跨域建仓等。
- 数据安全:备份恢复等能力。
- 数据质量:DQC自动校验等。
- 入湖建仓
- Job作业对于Workload的实际作业拆分和执行,以及调度到不同的计算平台上执行,对⽤户不可见;目前DLA只⽀持调度作业到DLA Serverless Spark上执行。核心单元概念如下:
- 全量作业(从某个Workload中拆分出来)
- 增量作业(从某个Workload中拆分出来)
- Clustering:小文件聚合
- Indexing:自动索引构建
- Compaction:自动日志合并
- Tier:自动分层存储
- Lifecycle:自动生命周期管理
- MaterializedView:物化视图
- DB(库):DLA的库
- Table(表):DLA的表
- Partition(分区):DLA的分区
- Column(列):DLA的列
DLA Lakehouse方案介绍
DLA Lakehouse实时入湖是分钟级近实时的数据入湖方案,它能够构建统一、低成本、海量数据、自动元信息同步的湖仓平台,并支持高性能的DLA Spark计算和DLA
Presto分析。DLA Lakehouse实时入湖方案的存储与计算完全分离,写、存、读完全弹性,它的方案架构如下图所示: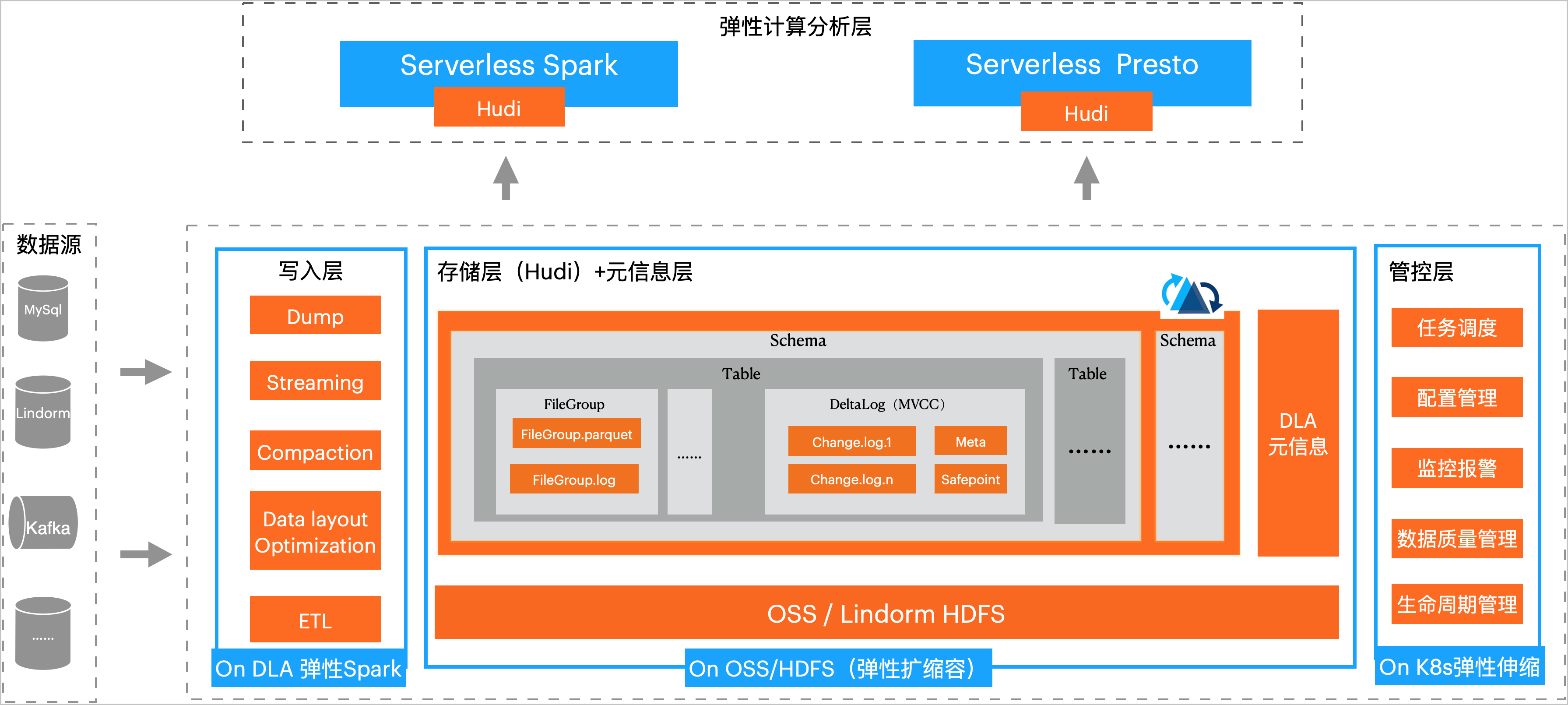
准备工作
您需要在DLA中进行以下操作:
- 开通云原生数据湖分析服务说明 如果未注册阿里云账号,请先注册账号。
- 创建虚拟集群说明 DLA基于Spark引擎来运行DLA Lakehouse,因此创建虚拟集群的时候需要选择Spark引擎。
您需要在RDS中进行以下操作:
- 创建RDS MySQL实例说明 由于DLA Lakehouse只支持专有网络,故创建RDS MySQL实例时,网络类型请选择专有网络。
- 创建数据库和账号
- 通过DMS登录RDS数据库
- 在SQLConsole窗口中执行SQL语句创建库表并插入数据。
您需要在DTS中进行以下操作:
说明 目前DLA中RDS数据源的入湖分析工作负载,会先利用RDS做数据的全量同步,然后依赖DTS数据订阅功能做增量同步,最终实现完整的RDS数据入湖。
- 创建RDS MySQL数据订阅通道说明
- 由于DLA Lakehouse只支持专有网络,故订阅任务的网络类型请选择专有网络。
- 由于DLA Lakehouse无法自动更新元数据信息,故需要订阅的数据类型请选择数据更新和结构更新。
- 新增消费组
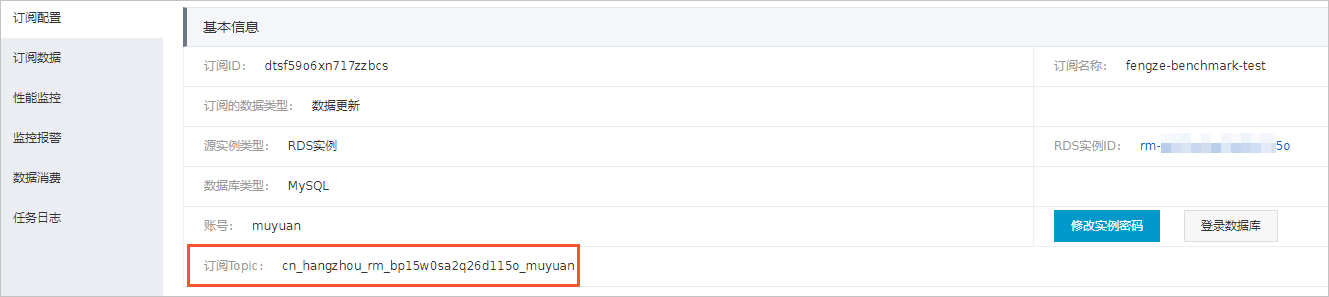
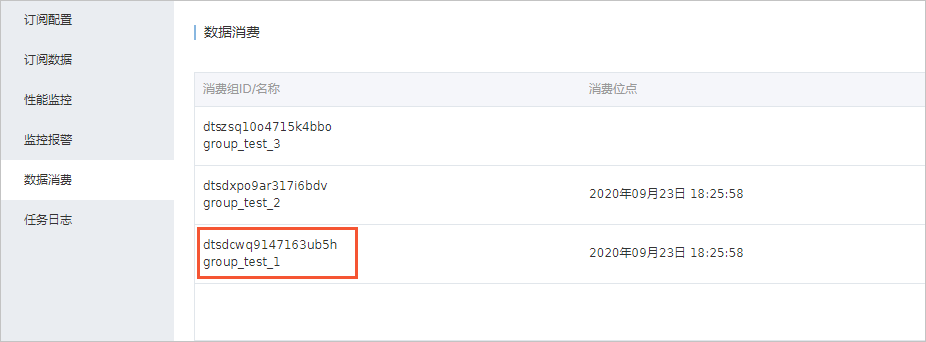
- 查看订阅Topic和消费者ID。后续的创建RDS入湖负载的增量同步配置中需要使用这2个参数。
- 在订阅任务的订阅配置中可以查看订阅Topic。
- 在订阅任务的数据消费中可以查看消费者ID。
- 在订阅任务的订阅配置中可以查看订阅Topic。
确保您的数据流在RDS中部署的区域与DTS、DLA、OSS的区域相同。
操作步骤
- 创建湖仓。
- 在新建湖仓页面进行参数配置。参数说明如下表所示:
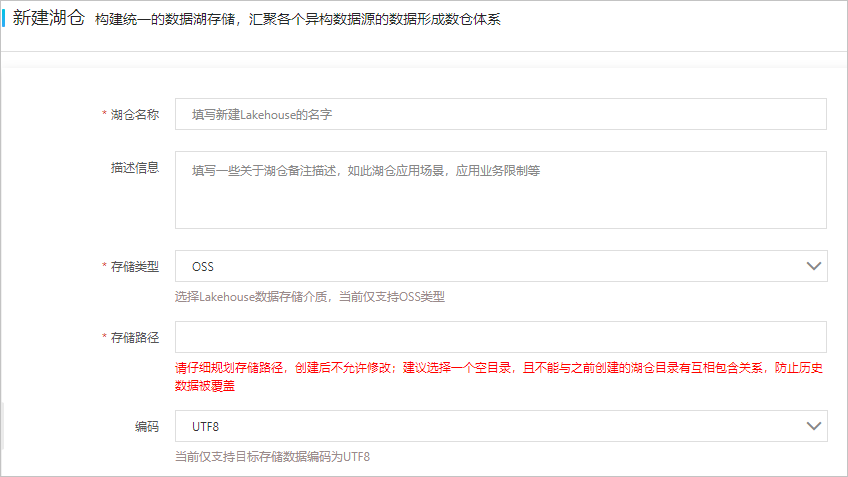
参数名称 参数说明 湖仓名称 DLA Lakehouse的名称。 描述信息 湖仓备注描述,例如湖仓应用场景、应用业务限制等。 存储类型 DLA Lakehouse数据的存储介质,当前仅⽀持OSS类型。 存储路径 DLA Lakehouse数据在OSS中的存储路径。 说明 请谨慎规划存储路径,创建后不允许修改。建议选择一个空目录,且不能与之前创建的湖仓目录有互相包含关系,防止历史数据被覆盖。编码 存储数据的编码类型,当前仅⽀持⽬标存储数据编码为UTF8。
湖仓创建成功后,湖仓列表页签中将展示创建成功的湖仓任务。
- 在新建湖仓页面进行参数配置。参数说明如下表所示:
- 创建入湖负载。
- 在新建工作负载页面,进行数据源的基础配置、全量同步配置、增量同步配置、生成目标数据规则配置。说明 当前仅支持RDS数据源和PolarDB数据源。
- 基础配置的参数说明如下:
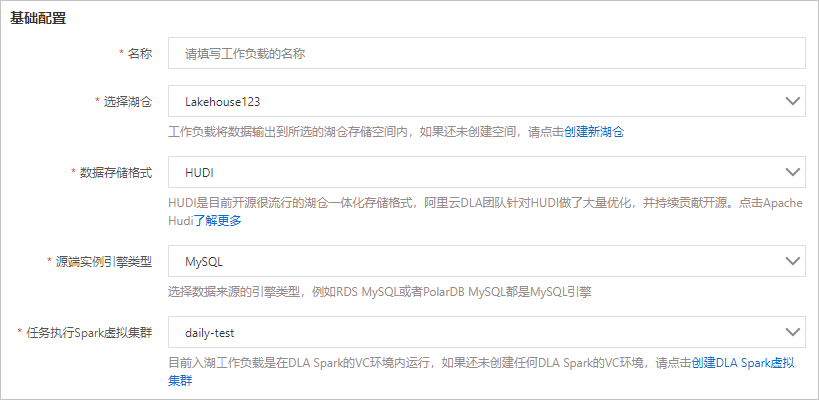
参数名称 参数说明 名称 工作负载的名称。 选择湖仓 工作负载将数据输出到所选的湖仓存储空间内。可下拉选择已经创建的湖仓。 数据存储格式 数据的存储格式固定为HUDI。 源端实例引擎类型 数据源的引擎类型。当前仅支持MySQL引擎。 任务执行Spark虚拟集群 执行Spark作业的虚拟集群。目前入湖⼯作负载在DLA Spark的虚拟集群中运行。如果您还未创建虚拟集群,请进行创建,具体请参见创建虚拟集群。 说明 请确保您选择的Spark虚拟集群处于正常运行状态,如果您选择的Spark虚拟集群处于非正常运行状态,启动工作负载时将失败。 - 全量同步配置的参数说明如下:
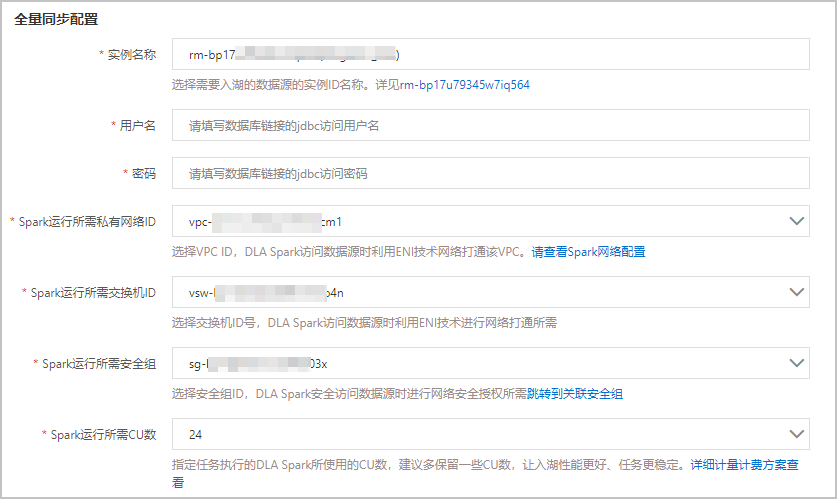
参数名称 参数说明 实例名称 选择需要入湖的数据源的实例ID名称。 用户名 需要入湖的数据源实例的访问用户名。 密码 需要入湖的数据源实例的访问密码。 Spark运行所需私有网络ID DLA Spark利用ENI技术配置该VPC网络来访问数据源。关于DLA Spark如何配置数据源VPC网络,请参见配置数据源网络。 Spark运行所需交换机ID DLA Spark运行所需VPC网络下的交换机ID。 Spark运行所需安全组 DLA Spark访问数据源时进行网络安全授权的安全组ID。您可以到RDS数据源实例的数据安全性页面中获取安全组ID,如未设置安全组请进行添加,具体操作请参见设置安全组。 Spark运行所需CU数 指定执行DLA Spark作业所使用的CU数,建议多保留一些CU数,让入湖性能更好、作业任务更稳定。 - 增量同步配置的参数说明如下:

参数名称 参数说明 同步方式 增量同步的通道类型。当前仅⽀持DTS⽅式。 订阅配置 增量同步所使用的DTS订阅通道配置,分别选择订阅Topic和消费组ID。 DTS用户名 增量同步DTS数据订阅消费组的账号信息。 DTS密码 增量同步DTS数据订阅消费组账号对应的密码信息。 Spark运行所需私有网络ID DLA Spark利用ENI技术配置该VPC网络来访问数据源。关于DLA Spark如何配置数据源VPC网络,请参见配置数据源网络。 Spark运行所需交换机ID DLA Spark运行所需VPC网络下的交换机ID。 Spark运行所需安全组 DLA Spark访问数据源时进行网络安全授权的安全组ID。您可以到RDS数据源实例的数据安全性页面中获取安全组ID,如未设置安全组请进行添加,具体操作请参见设置安全组。 Spark运行所需CU数 指定执行DLA Spark作业所使用的CU数,建议多保留一些CU数,让入湖性能更好、作业任务更稳定。 高级规则配置 - 消费位点:数据消费的时间点。当前取值固定为earliest,表示自动从最开始的时间点获取数据。
- 每批次消费记录条数:表示每次通过DTS拉取的数据量。
- 生成目标数据规则配置的参数说明如下:
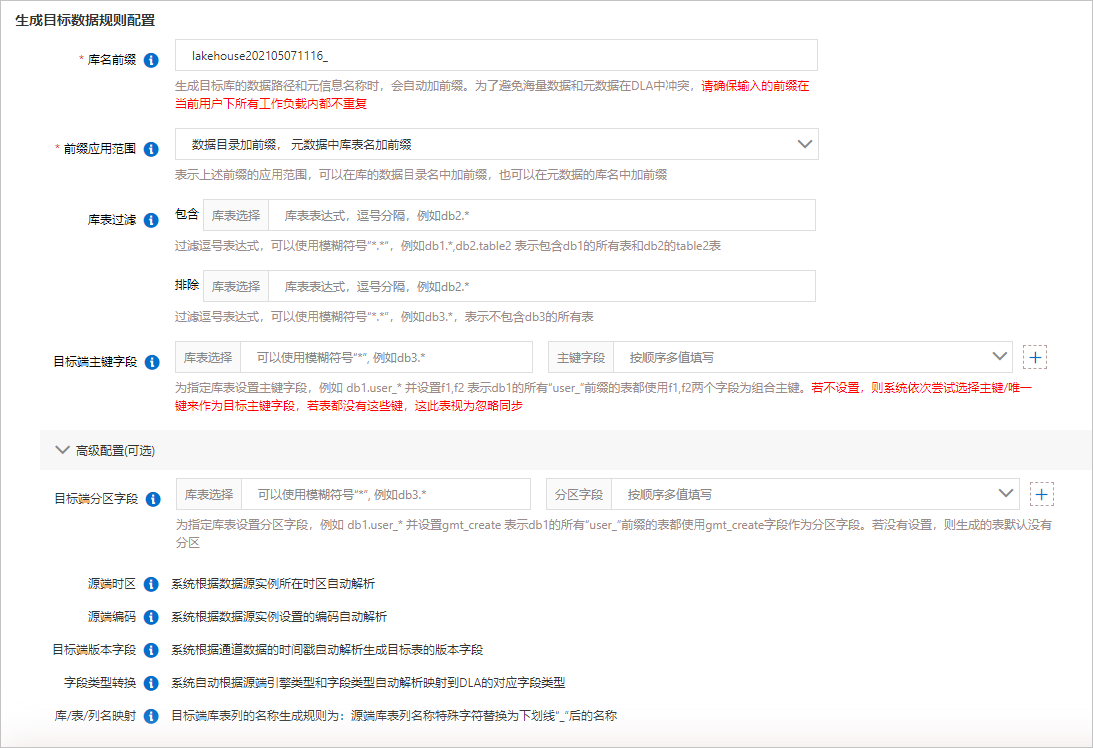
参数名称 参数说明 库名前缀 生成目标库的数据路径和元信息名称时,会自动添加该前缀。为了避免海量数据和元数据在DLA中冲突,请确保输入的前缀在当前阿里云账号下的所有工作负载内都不重复。 前缀应用范围 设置库名前缀的应用范围。包括: - 数据目录加前缀,元数据中库表名加前缀
- 数据目录不加前缀,元数据中库表名加前缀
库表过滤 设置需要同步的库和表范围。排除的优先级高于包含。 目标端主键字段 为指定库表设置主键字段。例如:库表选择输入 db1.user_*,主键字段输入f1,f2,表示db1的所有user_前缀的表都使⽤f1,f2两个字段作为组合主键。说明 如果不设置该参数,则系统依次尝试选择表中的主键或唯一键来作为目标端主键字段;如果表中不存在主键或唯一键,则视为忽略同步。高级配置 目标端分区字段:为指定库表设置分区字段。例如:库表选择输入
db1.user_*,分区字段输入gmt_create,表示db1的所有user_前缀的表都使⽤gmt_create字段作为分区字段。如果不设置该参数,则生成的表默认没有分区。
- 基础配置的参数说明如下:
入湖负载创建成功后,在工作负载列表页签中将展示创建成功的工作负载。
- 在新建工作负载页面,进行数据源的基础配置、全量同步配置、增量同步配置、生成目标数据规则配置。
- 启动工作负载。在工作负载列表页签中,定位到创建成功的入湖负载,在操作列单击启动。
 工作负载任务启动成功后,状态将由NO STATUS(未启动)变为RUNNING(运行中)。
工作负载任务启动成功后,状态将由NO STATUS(未启动)变为RUNNING(运行中)。 您还可以在操作列停止和校正工作负载任务、查看Spark日志。具体说明如下:
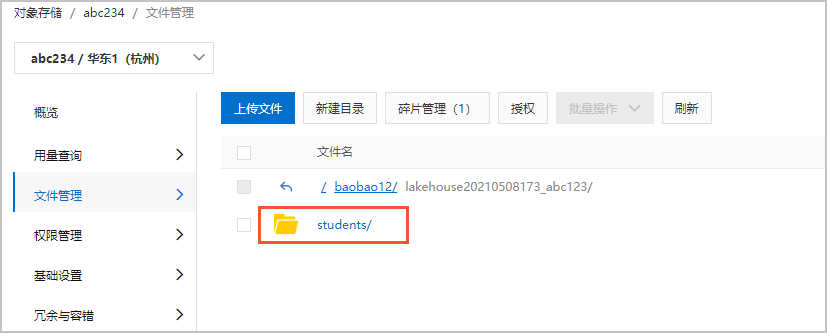
您还可以在操作列停止和校正工作负载任务、查看Spark日志。具体说明如下:操作按钮 含义 详情 单击该按钮,可以查看Spark日志或者UI,并定位工作负载任务启动失败原因。 停止 单击该按钮,可以停止工作负载任务。 校正 单击该按钮,可以对启动失败的工作负载任务进行数据校正。 说明 校正一般使用在库表变更、字段格式不一致等场景下。校正过程会重新进行部分存量数据的全量同步,请慎重填写库表筛选表达式,建议使用精确匹配表达式筛选,避免校正一些不必要的数据。如果未填写需要校正的库表,则校正失败。工作负载任务启动成功后,在湖仓列表页签单击存储路径下的OSS路径链接,可以跳转到OSS控制台查看已经从RDS数据源同步过来的库表路径以及表文件。- 数据库路径
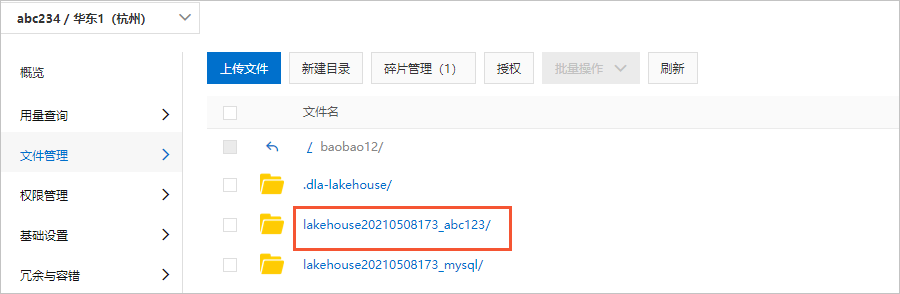
- 数据表路径
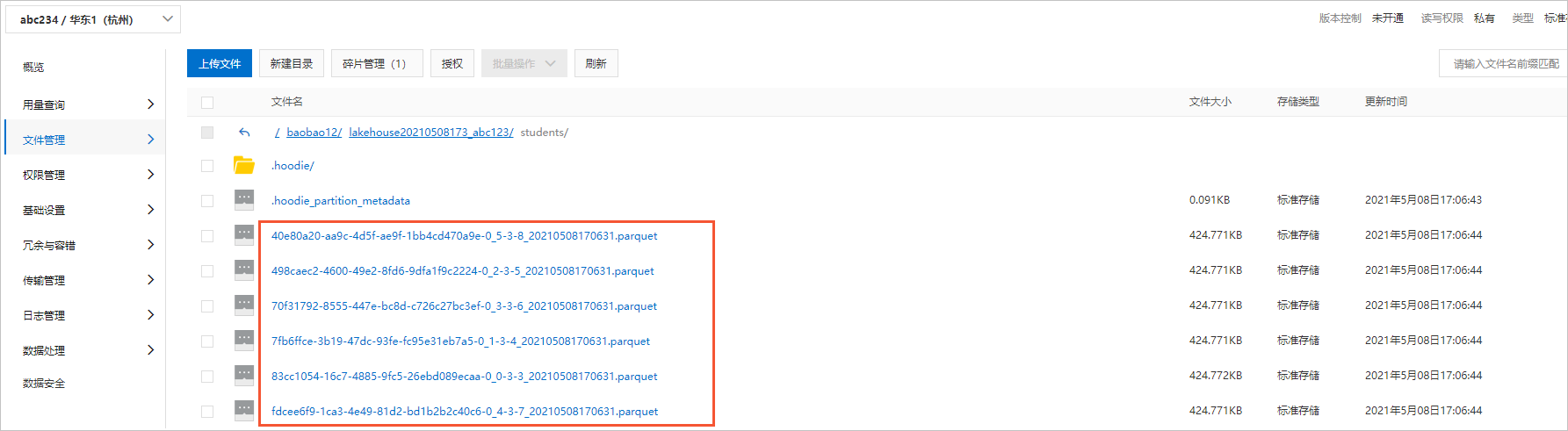
- 数据表文件
- 数据库路径
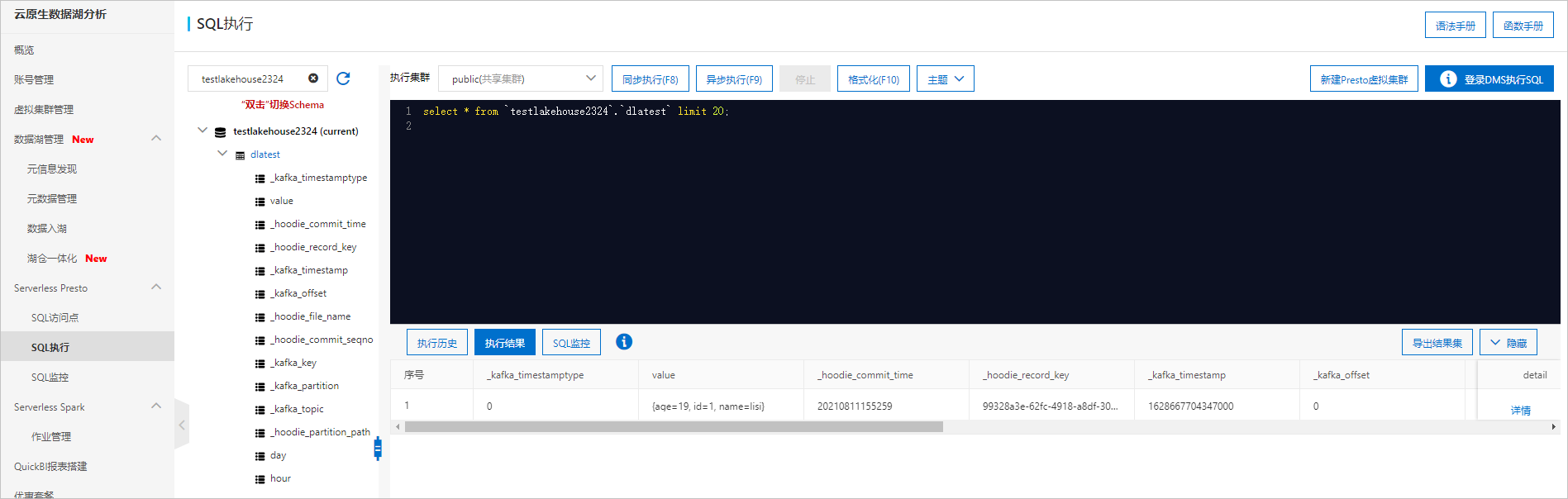
- 进行数据分析。工作负载任务启动成功后,在页面中,查看从RDS数据源同步过来的元数据信息。
 单击操作列的查询数据,在页面,查看从RDS数据源同步过来的全量表数据。
单击操作列的查询数据,在页面,查看从RDS数据源同步过来的全量表数据。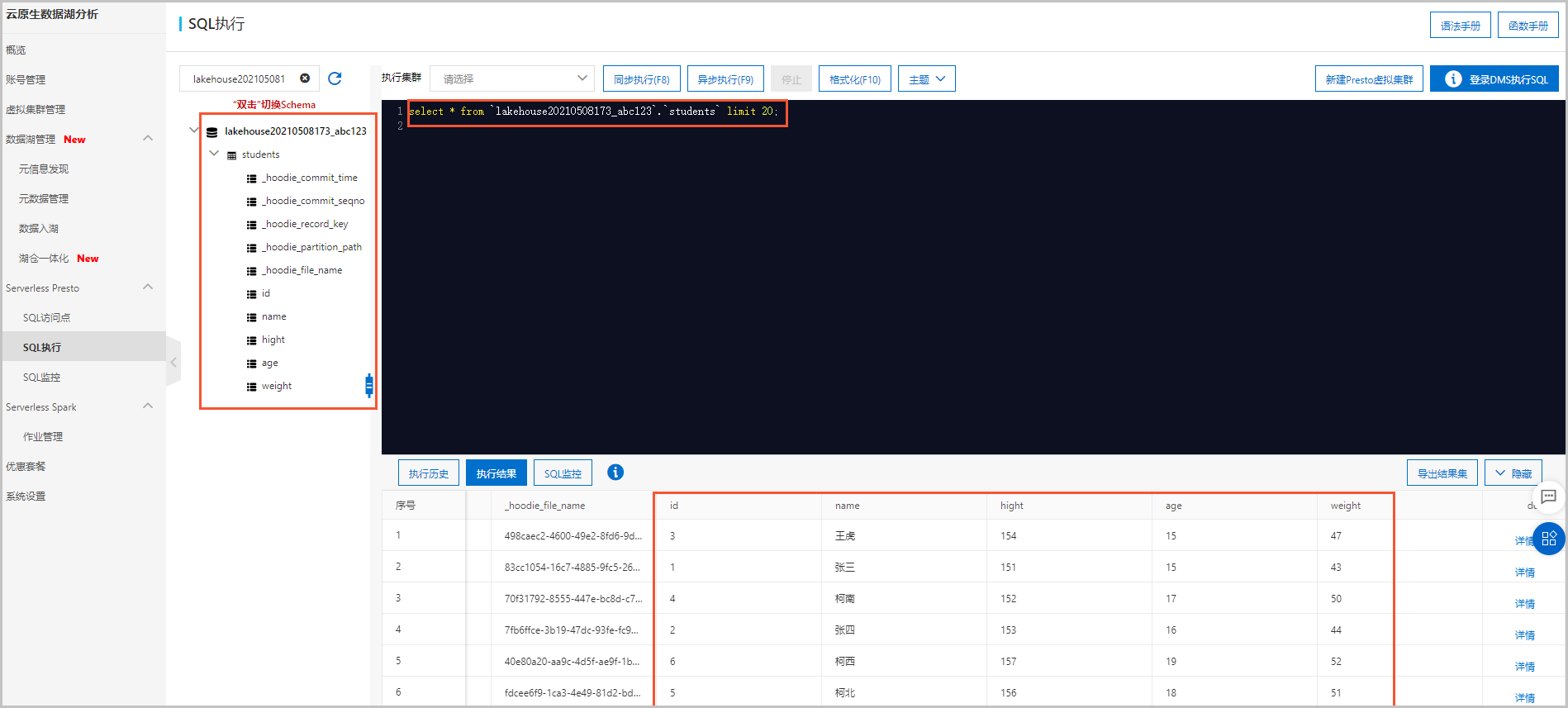 如果您在数据源RDS中变更了原始数据,在页面进行查询时,数据会同步进行更新。
如果您在数据源RDS中变更了原始数据,在页面进行查询时,数据会同步进行更新。