DLA Lakehouse实时入湖方案利用数据湖技术,重构数仓语义,分析数据湖数据,实现数仓的应用。本文介绍Kafka实时入湖建仓分析的操作步骤。
前提条件
- 已在DLA中开通云原生数据湖分析服务。更多信息,请参见开通云原生数据湖分析服务。
- 已创建Spark引擎的虚拟集群。更多信息,请参见创建虚拟集群。
- 如果您使用RAM子账号登录,还需要进行如下操作:
- 已授予RAM子账号AliyunDLAFullAccess权限。更多信息,请参见为RAM账号授权。
- 已将DLA子账号绑定到RAM子账号。更多信息,请参见DLA子账号绑定RAM账号。
- 已在Kafka中创建实例。更多信息,请参见创建实例。
- 已在Kafka中创建Topic。更多信息,请参见创建Topic。
- 已在Kafka中发送消息。更多信息,请参见发送消息。
方案介绍
DLA Lakehouse的Kafka实时入湖建仓分析助力企业实现”业务数据化”+“建仓”+“数据业务化”的数据闭环建设,主要包括三方面。
- Kafka实时入湖建仓引擎:支持T+10min近实时入湖,同时支持Schema推断及变更、嵌套打平、分区管理、小文件合并及Clustering等能力。
- OSS存储:入湖建仓基于OSS的低成本存储介质,有效地降低存储层成本,同时格式层使用HUDI格式来支持Append写入。
- 完全弹性的分析:DLA支持Serverless Presto和Serverless Spark的分析与计算能力,完全按需计费。
方案架构如下图所示。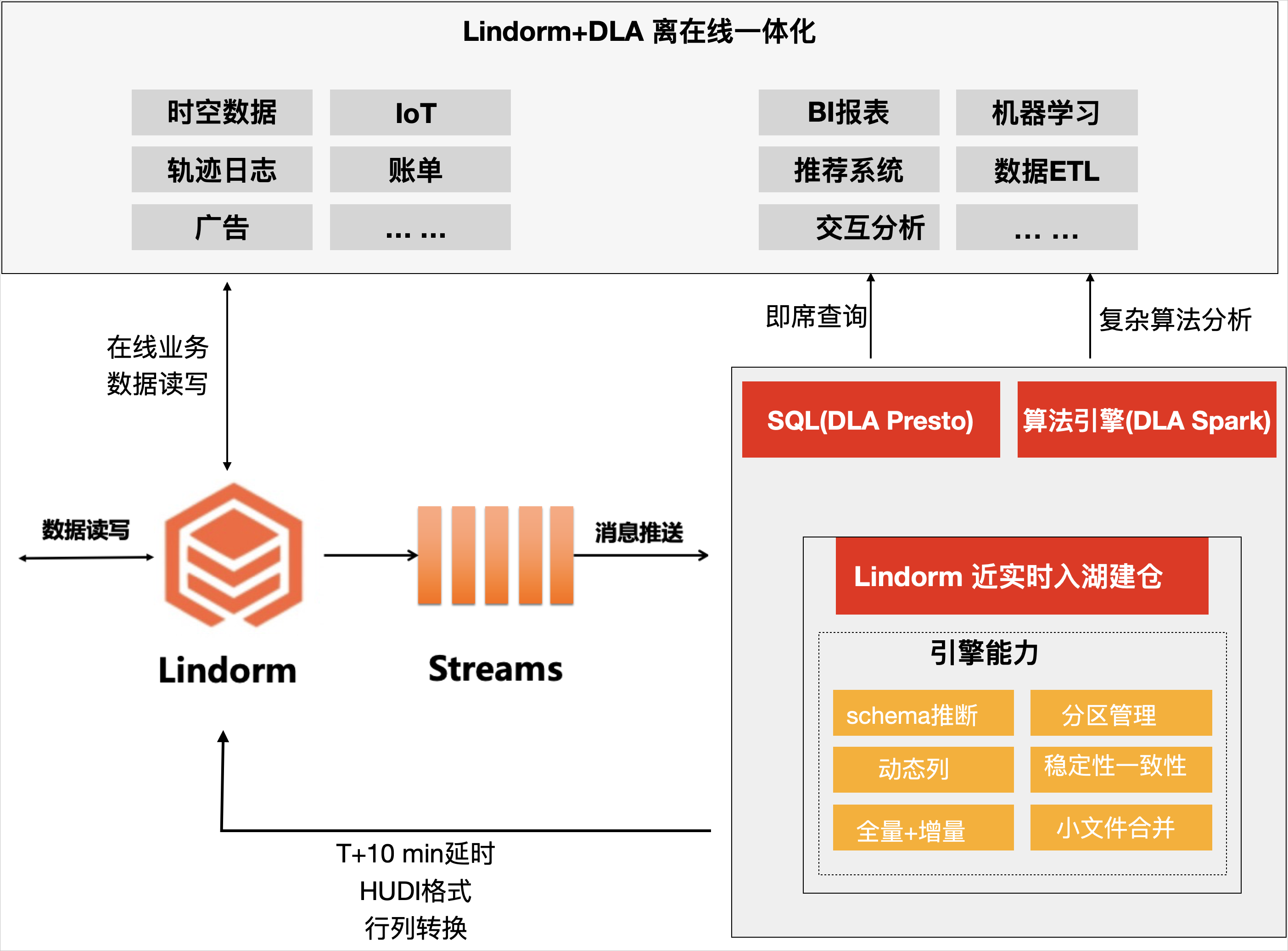
注意事项
Kafka中创建的Topic数据超过一定的时间会被自动清理,如果Topic数据过期,同时入湖任务失败,再重新启动时读取不到被清理掉的数据,会有丢失数据的风险。
授予RAM子账号创建库表的权限
如果您使用RAM子账号登录,在开始Kafka实时入湖的操作前,需要先授予RAM子账号创建库表的权限。
- 登录Data Lake Analytics控制台。
- 在左侧导航栏单击。
- 在右侧运行框输入如下语句,单击同步执行(F8)。
grant create,alter on *.* to user1_s1041577795224301;
操作步骤
- 创建湖仓。
- 在新建湖仓页面进行参数配置。参数说明如下表所示:
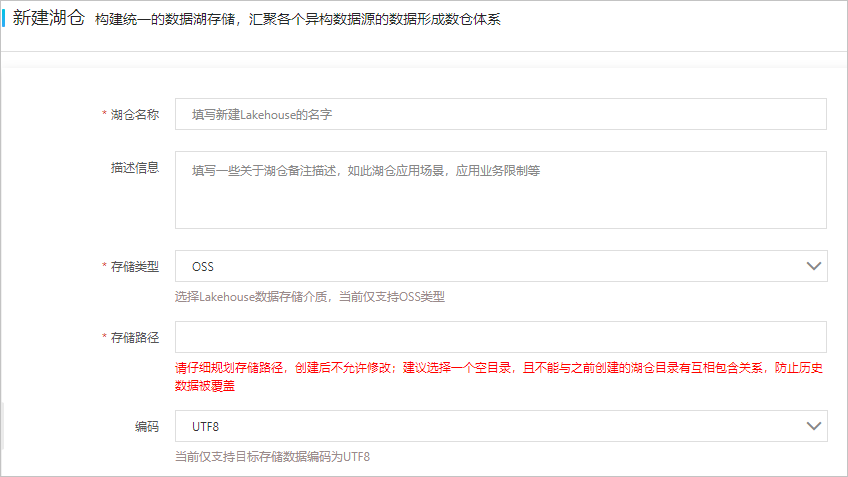
参数名称 参数说明 湖仓名称 DLA Lakehouse的名称。 描述信息 湖仓备注描述,例如湖仓应用场景、应用业务限制等。 存储类型 DLA Lakehouse数据的存储介质,当前仅⽀持OSS类型。 存储路径 DLA Lakehouse数据在OSS中的存储路径。 说明 请谨慎规划存储路径,创建后不允许修改。建议选择一个空目录,且不能与之前创建的湖仓目录有互相包含关系,防止历史数据被覆盖。编码 存储数据的编码类型,当前仅⽀持⽬标存储数据编码为UTF8。
湖仓创建成功后,湖仓列表页签中将展示创建成功的湖仓任务。
- 在新建湖仓页面进行参数配置。参数说明如下表所示:
- 创建入湖负载。
- 进行数据源的基础配置、增量同步配置、数据解析配置、生成目标数据规则配置。
- 基础配置的参数说明如下:
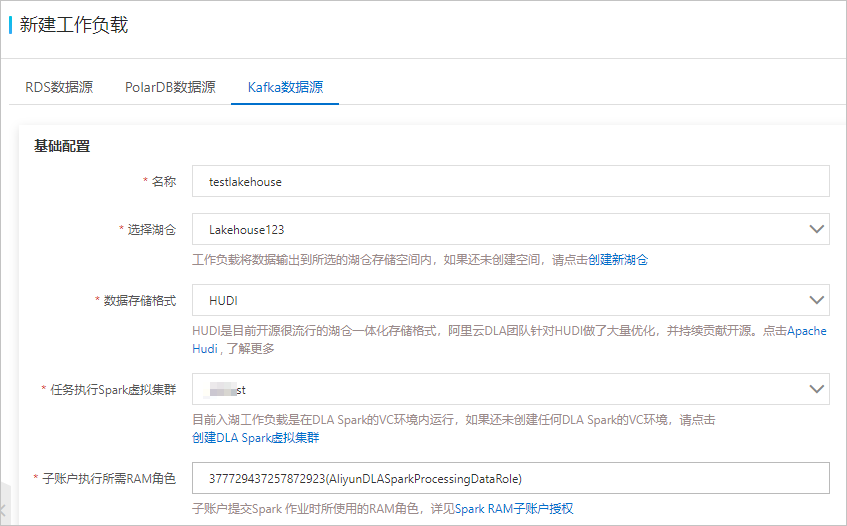
参数名称 参数说明 名称 工作负载的名称。 选择湖仓 下拉选择已经创建的湖仓,工作负载将数据输出到所选的湖仓内。 数据存储格式 数据的存储格式固定为HUDI。 任务执行Spark虚拟集群 执行Spark作业的虚拟集群。目前入湖⼯作负载在DLA Spark的虚拟集群中运行。如果您还未创建虚拟集群,请进行创建,具体请参见创建虚拟集群。 说明 请确保您选择的Spark虚拟集群处于正常运行状态,如果您选择的Spark虚拟集群处于非正常运行状态,启动工作负载时将失败。子账号执行所需RAM角色 子账号提交Spark作业时所使用的RAM角色,固定选择AliyunDLASparkProcessingDataRole。更多信息,请参见细粒度配置RAM子账号权限。 - 增量同步配置的参数说明如下:
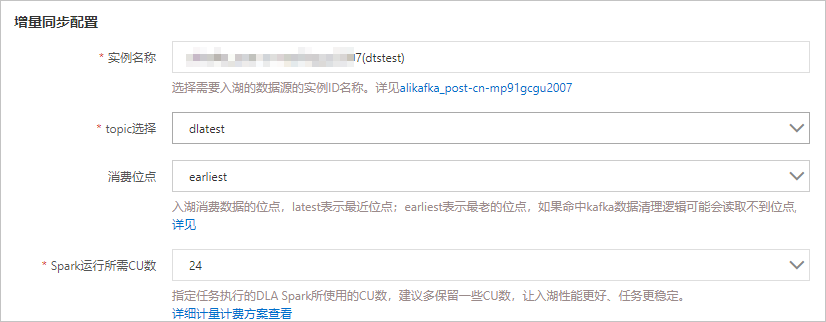
参数名称 参数说明 实例名称 选择需要入湖的数据源的实例ID和实例名称。 topic选择 在Kafka中创建的Topic名称。 消费位点 入湖消费数据的位点,latest表示最近位点;earliest表示最老的位点。更多信息,请参见消息队列Kafka版何时删除旧消息?。 Spark运行所需CU数 指定Kafka实时入湖任务所需DLA Spark的CU数。 - 数据解析配置的参数说明如下:
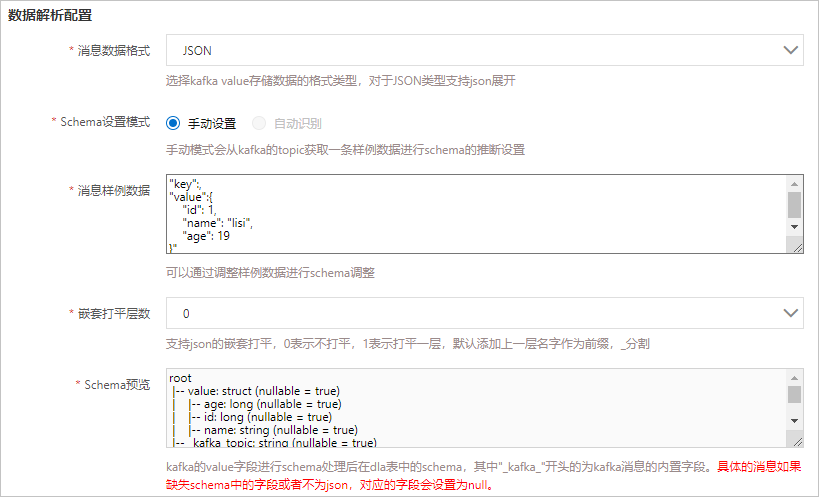
参数名称 参数说明 消息数据格式 Kafka的Value字段的数据存储格式,固定为JSON。 Schema设置模式 默认为手动设置,会从Kafka的Topic获取一条样例数据进行Schema的推断设置。 消息样例数据 通过调整样例数据对Schema进行调整。 嵌套打平层数 设置JSON的嵌套打平层数,取值如下。 - 0:不打平。
- 1:打平一层。
- 2:打平两层。
- 3:打平三层。
- 4:打平四层。
- 5:打平五层。
Schema预览 Kafka Value进行JSON解析的Schema模板,同时作为DLA表的Schema。 - 生成目标数据规则配置的参数说明如下:
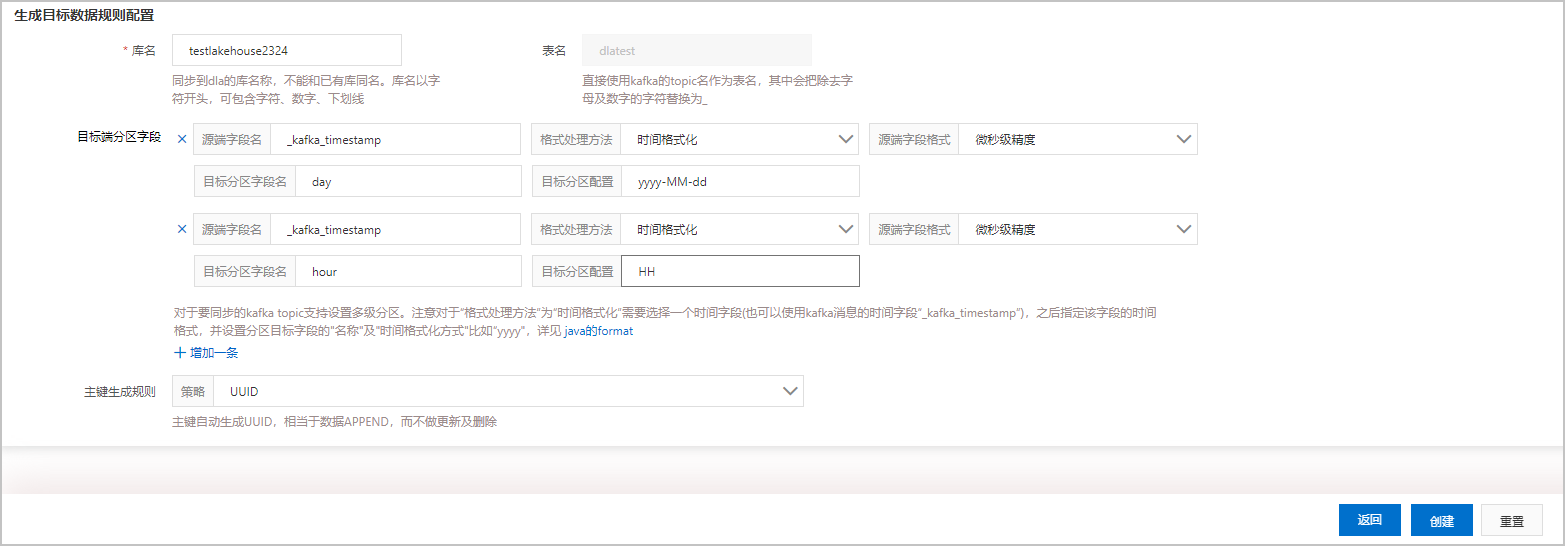
参数名称 参数说明 库名 目标DLA库的名称,库名以字符开头,可包含字符、数字、下划线,不能和已有库同名否则会报错。 表名 系统默认使用Kafka的Topic名作为表名,且不允许用户更改。 目标端分区字段 支持对要同步的Kafka Topic设置多级分区。您可以按需设置分区字段。 主键生成规则 仅支持UUID。UUID作为主键,数据只能新增插入,不能做更新和删除。
- 基础配置的参数说明如下:
入湖负载创建成功后,在工作负载列表页签中将展示创建成功的工作负载。
- 进行数据源的基础配置、增量同步配置、数据解析配置、生成目标数据规则配置。
- 启动工作负载。
- 在工作负载列表页签中,定位到创建成功的入湖负载,在操作列单击启动。
- 在弹出的再次确认窗口单击确定。
工作负载任务启动成功后,状态变为RUNNING。
- 进行数据分析。
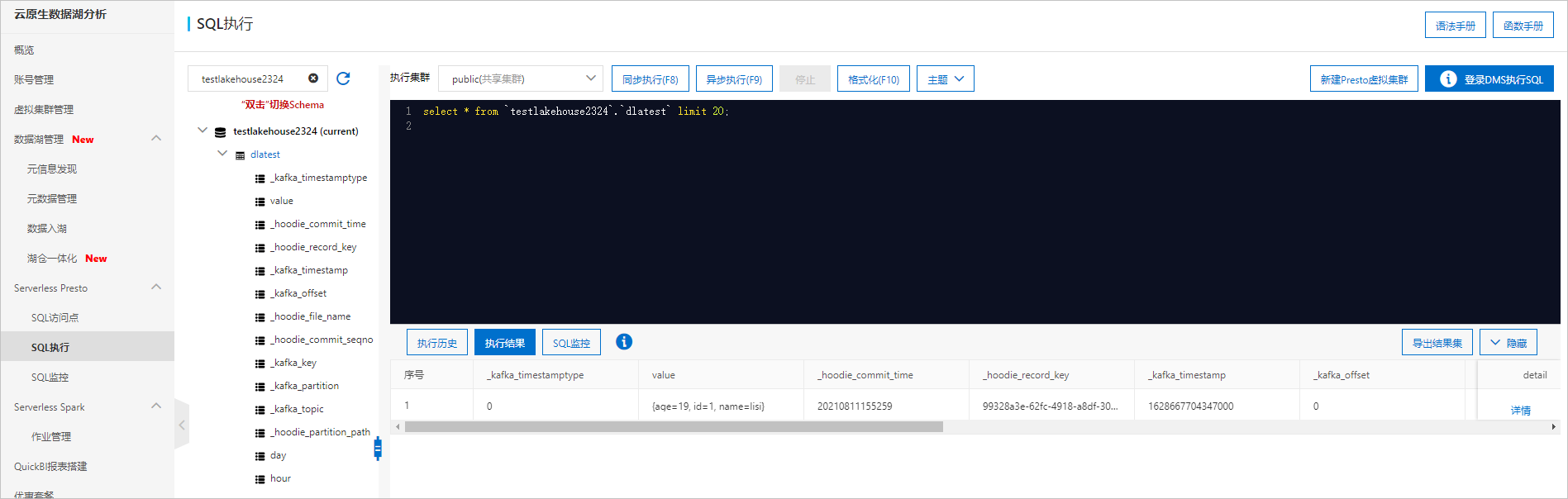
- 在工作负载列表页签单击入湖负载的库前缀。
- 在SQL执行页面,系统已经选中了目标库,您可以直接输入SQL语句进行数据分析。
- (可选)OSS数据存储管理。
- 在OSS控制台查看已经从Kafka数据源同步过来的库表路径以及表文件。
- 数据库路径:/lakehouse123/testlakehouse2324/。
- 表路径:/lakehousetest123/testlakehouse2324/dlatest。
- 表文件路径:/lakehousetest123/testlakehouse2324/dlatest/day=2021-8-11。
 重要 请勿删除从Kafka数据源同步过来的库表文件,否则会有丢失数据的风险。
重要 请勿删除从Kafka数据源同步过来的库表文件,否则会有丢失数据的风险。
- 在OSS控制台查看已经从Kafka数据源同步过来的库表路径以及表文件。